using Plots
using Random
functionenergy(x,b,w)
N = length(b)
term_1_body = sum( x .* b )
term_2_body = sum( w[i,j] * x[i] * x[j] for i =1:N for j = i:N)
E = term_1_body + term_2_body
return E
endfunctiondelta_energy(x,y,b,w)
return energy(y,b,w) - energy(x,b,w)
end
functionsample_BM(b,w;beta=1, max_iter=5000)
N = length(b) # number of spins
x = rand([-1,1],N) # initial spins
x_history = []
for iter =1:max_iter
trial_state = copy(x)
# Select one spin
target_spin_idx = rand(1:N)
# Flip the spinif trial_state[target_spin_idx] ==1#trial_state[target_spin_idx] = 0
trial_state[target_spin_idx] =-1else
trial_state[target_spin_idx] =1end
del_ene = delta_energy(trial_state,x,b,w)
if del_ene <0
x = trial_state
elseif del_ene >0
a = rand()
if a < exp(-beta * del_ene)
x = trial_state
endendif iter %1000==0@show iter
push!(x_history,x)
endend# you can see the state as # display( reshape(x, (L,M))')return x, x_history
end
あとは,相互作用wと磁場bを与えたら動きます.
2D Ising ならこんな感じです.
functiondefine_b_w(M,L,J,H)
N = M * L
b = H*ones(N)
w = zeros(N,N)
for m =0:M-1for l =1:L
if l < L
w[m*L+l, m*L+l+1] = J
endif1< l
w[m*L+l, m*L+l-1] = J
endif0< m
w[m*L+l, m*L+l-L] = J
endif m < M-1
w[m*L+l, m*L+l+L] = J
endendendreturn b,w
end
実行してみます.betaは逆温度で,Jが相互作用の強さ,Hが磁場の強さですね.
M =40; L =40; J =1; H =0.1; beta=0.1;
b, w = define_b_w(M,L,J,H);
x, x_history = sample_BM(b,w;beta=beta,max_iter=5000)
x = reshape(x, (L,M))';
plt=heatmap(x, aspect_ratio=:equal, axis=false, grid=false, size=(400,400), cbar=false)
outer(v...) = reshape(kron(reverse(v)...),length.(v))
functionget_low_CP_tensor(J, R)
D = length(J)
v =Vector{Array}(undef, D)
T = zeros(J...)
for r =1: R
for d =1: D
v[d] = rand(J[d])
end
T .+= outer(v...)
endreturn T
end
using LinearAlgebra
using Random
functionKL(A, B)
n, m = size(A)
kl =0.0for i =1:n
for j =1:m
kl += A[i,j] * log( A[i,j] / B[i,j] ) - A[i,j] + B[i,j]
endendreturn kl
endfunctionnmf_euc(X, r ; max_iter=200, tol =0.0001)
m, n = size(X)
W = rand(m, r)
H = rand(r, n)
error_at_init = norm(X - W*H)
previous_error = error_at_init
for iter in1:max_iter
H .= H .* ( W'* X ) ./ ( W'* W * H )
W .= W .* ( X * H') ./ ( W * H * H' )
if tol >0&& iter %10==0
error = norm(X - W*H)
if (previous_error - error) / error_at_init < tol
breakend
previous_error = error
endendreturn W, H
endfunctionnmf_kl(X, r ; max_iter=200, tol =0.0001)
m, n = size(X)
W = rand(m, r)
H = rand(r, n)
one_mn = ones(m, n)
error_at_init = KL(X, W*H)
previous_error = error_at_init
for iter in1:max_iter
println(KL(X, W*H))
H .= H .* ( W'* ( X ./ (W*H))) ./ ( W'* one_mn )
W .= W .* ( (X ./ (W*H) ) * H') ./ ( one_mn * H' )
if tol >0&& iter %10==0
error = KL(X, W*H)
if (previous_error - error) / error_at_init < tol
breakend
previous_error = error
endendreturn W, H
end
functionNNTF(A, r; max_iter=200, tol =0.0001)
C = A
r0 =1
d = ndims(A)
n = size(A)
G =Vector{Array{Float64}}(undef,d)
for i =1:(d-1)
if i ==1
C = reshape(C, (r0*n[i],:))
else
C = reshape(C, (r[i-1]*n[i],:))
end
W, H = nmf_euc(C, r[i], max_iter=max_iter, tol=tol)
H .= norm(W).* H
W .= W ./ norm(W)
if i ==1
G[i] = reshape(W, (1, n[i], r[i]))
else
G[i] = reshape(W, (r[i-1], n[i], r[i]))
end
C = H
end
G[d] = reshape(C, (r[d-1],n[d],1))
return G
end
outer(v...) = reshape(kron(reverse(v)...),length.(v))
functionreconst_train(G)
D = length(G)
sizesG = size.(G)
R = zeros(Int64,D)
J = zeros(Int64,D)
for d =1:D
R[d] = sizesG[d][1]
J[d] = sizesG[d][2]
end
rs = ( (1:R[d]) for d in1:D)
term = zeros(Float64, J...)
for r in product(rs...)
v =Vector{Array{Float64}}(undef, D)
for d =1:D
if d ==1
v[d] = G[1][ 1, :, r[2]]
elseif d == D
v[d] = G[D][ r[D], :, 1]
else
v[d] = G[d][ r[d], :, r[d+1]]
endend
term += outer(v...)
endreturn term
end
using LinearAlgebra
using TensorToolbox
functionget_low_tucker_tensor(J,R)
G = rand(R...)
D = length(J)
U =Vector{Matrix{Float64}}(undef,D)
for d =1:D
U[d] = rand(J[d],R[d])
end
T = ttm(G, [U...], [1:D;])
return T
end
using LinearAlgebra
using TensorToolbox
functionreconst(F)
D = ndims(F)
R = length(F.lambda)
F1 = F.lambda[1] * ttt(F.fmat[1][:,1], F.fmat[2][:,1])
for d =3:D
F1 = ttt(F1, F.fmat[d][:,1])
endfor r =2:R
Fr = F.lambda[r] * ttt(F.fmat[1][:,r], F.fmat[2][:,r])
for d =3:D
Fr = ttt(Fr, F.fmat[d][:,r])
end
F1 .= F1 .+ Fr
endreturn F1
end
functionkernel_function(kernel)
if kernel =="rbf"return (x,y,c,deg) -> exp( -c*norm(x.-y)^2 )
elseif kernel =="lapras"return (x,y,c,deg) -> exp(-c*sum( abs.(x .- y)))
elseif kernel =="poly"return (x,y,c,deg) -> (c+x'*y)^deg
elseif kernel =="linear"return (x,y,c,deg) -> (0+x'*y)^1elseif kernel =="periodic"return (x,y,c,deg) -> exp(deg* cos(c * norm(x .- y)))
else
error("Kernel $kernel is not defined")
endendfunctionKernel(X::Matrix, Y::Matrix; c=1.0, deg=3.0, kernel="rbf")
kf = kernel_function(kernel)
d, n = size(X)
d, m = size(Y)
K =Matrix{Float64}(undef, m, n)
for j =1:n
for i =1:m
K[i,j] = kf(Y[:,i],X[:,j],c,deg)
endendreturn K
endfunctionKernel(X::Matrix; c=1.0, deg=3.0, kernel="rbf")
kf = kernel_function(kernel)
d, n = size(X)
K =Matrix{Float64}(undef, n, n)
for j =1:n
for i =1:j
K[i,j] = kf(X[:,i],X[:,j],c,deg)
endendreturnSymmetric(K)
end
次に本体とnystrom法.
using LinearAlgebra
include("kernels.jl")
"""low-rank approximation based on random sampling.See the following reference,[Petros Drineas et al.](https://www.jmlr.org/papers/v6/drineas05a.html)# Aruguments- 'K' : input positive definite matrix.- 'p' : target rankexample: A = randn(100,100) K = A*A' for p in [1,5,10,20,30,50,100] Kr = nystrom(K, p) @show p, norm(K-Kr) end"""functionnystrom(K,p)
n, n = size(K)
idxs = sample(1:n, p, replace=false, ordered=false)
C = K[:,idxs]
W = K[idxs,idxs]
invWct = W \ C'return C, invWct
endfunctionKreg(X_train, Y_train, X_test;lambda=1, c=1, deg=3.0, kernel="rbf", sampling=false, p=10)
K_train_train = Kernel(X_train, c=c, deg=deg, kernel=kernel)
k_train_test = Kernel(X_train, X_test, c=c, deg=deg, kernel=kernel)
# number of test data
M = size(X_test)[2]
# number of target variables
N = size(Y_train)[1]
Y_pred = zeros(N,M)
for n =1:N
if sampling
C, invWCt = nystrom(K_train_train, p)
alpha =1.0/ lambda .* ( I - C* ((lambda*I + invWCt*C) \ invWCt) ) * Y_train[n,:]
else
alpha = (K_train_train + lambda * I) \ Y_train[n,:]
end
Y_pred[n,:] .= k_train_test * alpha
endreturn Y_pred
end
main()
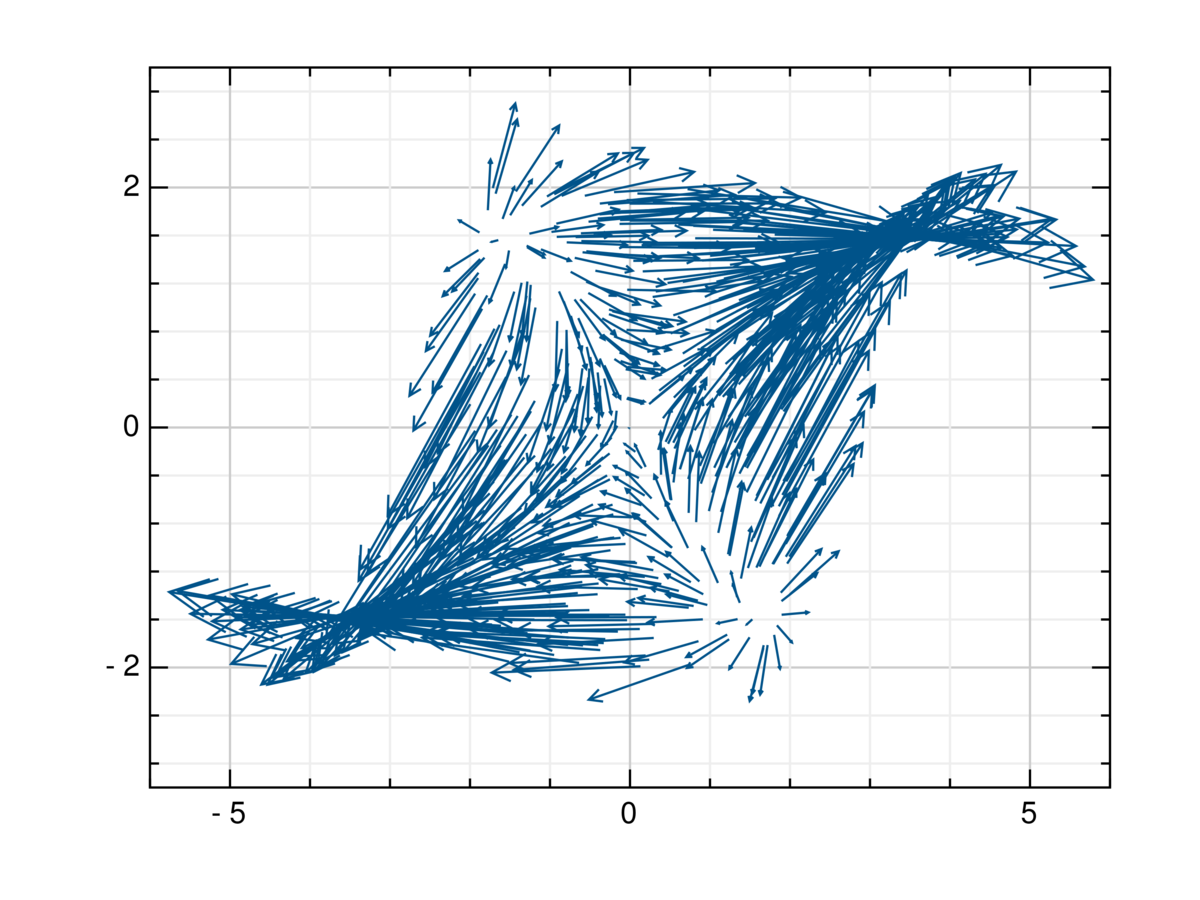
適当な3次元ベクトル場を学習してみる.とりあえずデータ数13000でやってみよう.
using Distributions
using BenchmarkTools
functionmake_vector_field(L)
f(x,y,z) = [x+y+z, x*cos(y)-y, -y+x+z]
dist = Uniform(-2, 2)
x = rand(dist,(3, L))
y =Matrix{Float64}(undef, 3, L)
for i =1:L
y[:,i] = f(x[:,i]...)
endreturn x, y
endfunctioneval(y_test, y_pred)
L = length(y_test)
cost = norm(y_test[:] .- y_pred[:])^2/ L
return cost
endfunctionmain()
x_train, y_train = make_vector_field(13000)
x_test, y_test = make_vector_field(100)
y_pred_0 = Kreg(x_train, y_train, x_test, kernel="rbf" ,lambda=1, c=1, sampling=false)
@show norm(y_pred_0 - y_test)
@btime Kreg($x_train, $y_train, $x_test, kernel="rbf" ,lambda=1, c=1, sampling=false)
println("")
ps = [5,10,20,30,40,50,100]
for p in ps
y_pred = Kreg(x_train, y_train, x_test, kernel="rbf" ,lambda=1, c=1, sampling=true, p=p)
@show p, norm(y_pred - y_test)
@btime Kreg($x_train, $y_train, $x_test, kernel="rbf" ,lambda=1, c=1, sampling=true, p=$p)
println("")
endend
using LinearAlgebra
using StatsBase
"""low-rank approximaion based on random sampling.See the following reference,[Petros Drineas et al.](https://www.jmlr.org/papers/v6/drineas05a.html)# Aruguments- 'K' : input positive definite matrix.- 'p' : target rankexample: A = randn(100,100) K = A*A' for p in [1,5,10,20,30,50,100] Kr = nystrom(K, p, reconst=true) @show p, norm(K-Kr) end"""functionnystrom(K,p;reconst=false)
n, n = size(K)
idxs = sample(1:n, p, replace=false, ordered=false)
C = K[:,idxs]
W = K[idxs,idxs]
if reconst ==truereturn C*( W \ C')
elsereturn C, inv(W)
endend
using LinearAlgebra
functionkernel_function(kernel)
if kernel =="rbf"return (x,y,c,deg) -> exp( -c*norm(x.-y)^2 )
elseif kernel =="lapras"return (x,y,c,deg) -> exp(-c*sum( abs.(x .- y)))
elseif kernel =="poly"return (x,y,c,deg) -> (c+x'*y)^deg
elseif kernel =="linear"return (x,y,c,deg) -> (0+x'*y)^1elseif kernel =="periodic"return (x,y,c,deg) -> exp(deg* cos(c * norm(x .- y)))
else
error("Kernel $kernel is not defined")
endendfunctionKernel(X::Matrix, Y::Matrix; c=1.0, deg=3.0, kernel="rbf")
kf = kernel_function(kernel)
d, n = size(X)
d, m = size(Y)
K =Matrix{Float64}(undef, m, n)
for j =1:n
for i =1:m
K[i,j] = kf(Y[:,i],X[:,j],c,deg)
endendreturn K
endfunctionKernel(X::Matrix; c=1.0, deg=3.0, kernel="rbf")
kf = kernel_function(kernel)
d, n = size(X)
K =Matrix{Float64}(undef, n, n)
for j =1:n
for i =1:j
K[i,j] = kf(X[:,i],X[:,j],c,deg)
endendreturnSymmetric(K)
endfunctionvecKernel(X::Matrix, dim_output::Int; c=1, deg=3.0, omega=0.5, kernel="rbf", block_kernel="ones")
kf = kernel_function(kernel)
_, n = size(X)
K =Matrix{Float64}(undef, n*dim_output, n*dim_output)
for j =1:n
for i =1:j
K[(i-1)*dim_output+1:i*dim_output,(j-1)*dim_output+1:j*dim_output] = (
kf(X[:,i], X[:,j],c,deg) *
block_kernel_A(X[:,i], X[:,j], dim_output, block_kernel, c, omega)
)
endendreturnSymmetric(K)
endfunctionvecKernel(X::Matrix, Y::Matrix; c=1, deg=3.0, omega=0.5, kernel="rbf", block_kernel="ones")
kf = kernel_function(kernel)
dim_input, n = size(X)
dim_output, m = size(Y)
K =Matrix{Float64}(undef, m*dim_output, n*dim_output)
for j =1:n
for i =1:m
K[(i-1)*dim_output+1:i*dim_output,(j-1)*dim_output+1:j*dim_output] = (
kf(Y[:,i], X[:,j],c,deg) *
block_kernel_A(Y[:,i], X[:,j], dim_output, block_kernel, c, omega)
)
endendreturn K
end"""The matrix `A` represent the relation betweenoutput elements. If `A` is `I`, the outputs are independent."""functionblock_kernel_A(xi::Vector, xj::Vector, dim_output::Int, block_kernel, c, omega)
if block_kernel =="id"
A =Matrix{Float64}(I,dim_output,dim_output)
elseif block_kernel =="ones"
A = ones(Float64, dim_output, dim_output)
elseif block_kernel =="ones_id"
A = ( omega*ones(Float64, dim_output, dim_output)
.+ (1-omega*dim_output)*Matrix{Float64}(I, dim_output, dim_output))
elseif block_kernel =="df"@assert dim_output == size(xi)[1]
"df is available only when dim of input and output are same"
A = block_kernel_df(xi,xj,c=c)
elseif block_kernel =="cf"@assert dim_output == size(xi)[1]
"cf is available only when dim of input and output are same"
A = block_kernel_cf(xi,xj,c=c)
else
error("block kernel $block_kernel is not defined")
endreturn A
end"""Divergence-free kernel.The dim of output variable and input variable have to be same.The variance 1/σ^2 = c"""functionblock_kernel_df(xi::Vector, xj::Vector; c=1)
m = size(xi)[1]
dx = xi .- xj
normdx_2 = norm(dx)^2
A =2*c*(2*c*(dx*dx')+(m-1-2*c*normdx_2)*I)
return A
end"""Curl-free kernel.The dim of output variable and input variable have to be same.The variance 1/σ^2 = c"""functionblock_kernel_cf(xi::Vector, xj::Vector; c=1)
m = size(xi)[1]
dx = xi .- xj
A =2*c*( Matrix{Float64}(I,m,m) -2* c * (dx * dx'))
return A
end"""Vector-valud function learning with kernel method.See the following references,[Mauricio Alvarez et al.](https://ieeexplore.ieee.org/document/8187598)[Luca Baldassare et al.](https://link.springer.com/article/10.1007/s10994-012-5282-y)Learn the projection f(x) : x -> y, where both of x and y are vectorvalued.Let us assume x is in R^k, y is in R^d.n is the number of the training data.k is the number of the test data.# Arguments- 'X_train' : k \times n matrix, training data of input- 'Y_train' : d \times n matrix, training data of output- 'X_test' : d \times m matrix, test data of input.- 'kernel' : 'rbf','lapras','poly','linear','periodic'- 'block_kernel' : 'id', 'ones', 'df', 'cf'. if you chouse 'id', the elements of output are independent each other.- 'lambda' : the value of regularization paramter"""functionmultiKreg(X_train, Y_train, X_test; kernel="rbf", block_kernel="df", lambda=1.0, c=1.0, deg=3.0, omega=0.5)
# dim of output variable
d = size(X_train)[1]
# number of test data
n = size(X_test)[2]
K_train_train = vecKernel(X_train, d, c=c, deg=deg, omega=omega, kernel=kernel, block_kernel=block_kernel)
K_train_test = vecKernel(X_train, X_test, c=c, deg=deg, omega=omega, kernel=kernel, block_kernel=block_kernel)
# in the original paper, they define# c_vec = (K_train_train + lambda*n*I) \ Y_train[:]
c_vec = (K_train_train + lambda*I) \ Y_train[:]
Y_pred = K_train_test * c_vec
Y_pred = reshape(Y_pred, (:,n))
return Y_pred
end
using LinearAlgebra
functionKreg(X_train, Y_train, X_test;lambda=1, c=1, deg=3.0, kernel="rbf")
K_train_train = Kernel(X_train, c=c, deg=deg, kernel=kernel)
k_train_test = Kernel(X_train, X_test, c=c, deg=deg, kernel=kernel)
# number of test data
M = size(X_test)[2]
# number of target variables
N = size(Y_train)[1]
Y_pred = zeros(N,M)
for n =1:N
alpha = (K_train_train + lambda * I) \ Y_train[n,:]
Y_pred[n,:] .= k_train_test * alpha
endreturn Y_pred
end
using Arpack
using LinearAlgebra
functionget_eigen_system(K, rank; eigen_method="lapack")
n = size(K)[1]
if eigen_method =="lapack"
f = eigen(K, sortby=-)
lambda = f.values
alpha = f.vectors
elseif eigen_method =="lapack_sym"
lambda, alpha = eigen(K, n-rank+1:n)
lambda .= lambda[end:-1:1]
alpha .= alpha[:, end:-1:1]
elseif eigen_method =="arpack"
lambda, alpha = eigs(K, nev=rank, which=:LR)
elseif eigen_method =="nys"
lambda, alpha = evdnys(K, rank, reconst=false)
elseif eigen_method =="randomized"
lambda, alpha = reigen(K, rank, reconst=false)
else
error("Eigenvalue Decomposion method $eigen_method is not defined")
endreturn lambda, alpha
end
何度も載せているが,nysとrandomizedの実装はこちら.
using LinearAlgebra
"""Randomized eigenvalue decomposition via Nystrom Method.See Fig 6 in the [original paper](https://arxiv.org/abs/1607.01649)or See Algorithm 5.5 in the [original paper](https://epubs.siam.org/doi/10.1137/090771806)This method is available for only a positive definite matrix.# Aruguments- 'A' : input positive definite matrix- 'k' : target rank, number of wanted eigenvalues- 'p' : over-sampling parameter, it should be 10 or 2k.- 'reconst' : if ture, the output is reconstracted matrix which approximates 'A'example: # make a positive definite matrix `A`. n = 5000; m = 25000; x = randn(m,n) demean_x = x .- mean(x, dims=1) A = demean_x'*demean_x ./(m-1) # run evdnys lowrank_mtx = evdnys(A,10, reconst=true)"""functionevdnys(A::Symmetric, k::Int;p=10, reconst=false)
n, n = size(A)
G = randn(n, k+p)
Y = A * G
Q = qr(Y).Q*Matrix(I,n,k+p)
B1 = A*Q
B2 = Q'*B1
C = cholesky(Symmetric(B2))
#F = B1 * inv(C.U)
F = B1 / C.U
U, Σ, _ = svd(F)
if reconst
return U*diagm(Σ.^2)*U'elsereturn Σ.^2, U
endend"""Randomized eigenvalue decomposition proposed by N.halko et al.See Algorithm 5.6. in the[original paper](https://epubs.siam.org/doi/10.1137/090771806).This method is effective matrices with decaying eigenvalues.# Aruguments- 'A' : input positive definite matrix- 'r' : target rank, number of wanted eigenvalues- 'p' : over-sampling parameter, it should be 10 or 2r.- 'reconst' : if ture, the output is reconstracted matrix which approximates 'A'example: # make a matrix with decaying eigenvalues n = 150; A = rand(n,n); B = zeros(n,n) e, v = eigen(Symmetric(A)) for i in 1:n B += e[i] * v[:,i] * v[:,i]' * (i>n-100 ? 1 : 1e-3) end # run reigen lowrank_mtx = reigen(A, 10, reconst=true)"""functionreigen(A, r ;p=10, twopass=false, reconst=false)
n = size(A)[1]
m = r + p
Ω = randn(n, m)
Y = A*Ω
if twopass
Q = qr!(Y).Q *Matrix(I,n,m)
T = Q'* A * Q
else
Q = qr(Y).Q *Matrix(I,n,m)
T = (Q'* Y) / ( Q'* Ω )
end
λ, S = eigen(T)
U = Q*S'if reconst
Λ =Diagonal(λ)
return U*Λ*U'elsereturn λ,U
endend
数値計算で逆行列の計算を避けましょうというのはもはや常識と思います.例えば,givenの行列AとBについて,C = inv(A) * B を計算したいときは,左除算演算子\を使って
using LinearAlgebra
C = A \ B
とした方が速いです.実際に
using BenchmarkTools
n =6000
A = rand(n,n)
B = rand(n,n)
@btime inv($A) *$B# 3.458 s (8 allocations: 552.29 MiB)@btime$A\$B# 2.206 s (6 allocations: 552.29 MiB)
念のため,inv(A) * B と A \ B がほとんど同じ出力であることを確認しておきます.
norm( inv(A) * B - A \ B)
#2.2633599357010303e-9
一方で,C = B * inv(A)を高速に計算したいときはどうしたらよいのでしょうか.こういう時は,実は右除算演算子/を使えばよいらしいです.知らなかったので,早速比較実験してみると
@btime$B* inv($A)
# 3.474 s (8 allocations:980.53 MiB)@btime$B/$A# 2.717 s (8 allocations: 976.62 MiB)
using LinearAlgebra
"""Randomized eigenvalue decomposition via Nystrom Method.See Fig 6 in the [original paper](https://arxiv.org/abs/1607.01649)or See Algorithm 5.5 in the [original paper](https://epubs.siam.org/doi/10.1137/090771806)This method is available for only a positive definite matrix.# Aruguments- 'A' : input positive definite matrix- 'k' : target rank, number of wanted eigenvalues- 'p' : over-sampling parameter, it should be 10 or 2k.- 'reconst' : if ture, the output is reconstracted matrix which approximates 'A'example: # make a positive definite matrix `A`. n = 5000; m = 25000; x = randn(m,n) demean_x = x .- mean(x, dims=1) A = demean_x'*demean_x ./(m-1) # run evdnys lowrank_mtx = evdnys(A,10, reconst=true)"""functionevdnys(A::Symmetric, k::Int;p=10, reconst=false)
n, n = size(A)
G = randn(n, k+p)
Y = A * G
Q = qr(Y).Q*Matrix(I,n,k+p)
B1 = A*Q
B2 = Q'*B1
C = cholesky(Symmetric(B2))
#F = B1 * inv(C.U)
F = B1 / C.U
U, Σ, _ = svd(F)
if reconst
return U*diagm(Σ.^2)*U'elsereturn U, Σ.^2endend"""Randomized eigenvalue decomposition proposed by N.halko et al.See Algorithm 5.6. in the[original paper](https://epubs.siam.org/doi/10.1137/090771806).This method is effective matrices with decaying eigenvalues.# Aruguments- 'A' : input positive definite matrix- 'r' : target rank, number of wanted eigenvalues- 'p' : over-sampling parameter, it should be 10 or 2r.- 'reconst' : if ture, the output is reconstracted matrix which approximates 'A'example: # make a matrix with decaying eigenvalues n = 150; A = rand(n,n); B = zeros(n,n) e, v = eigen(A) for i in 1:n B += e[i] * v[:,i] * v[:,i]' * (i>n-100 ? 1 : 1e-3) end # run reigen lowrank_mtx = reigen(A, 10, reconst=true)"""functionreigen(A, r ;p=10, twopass=false, reconst=false)
n = size(A)[1]
m = r + p
Ω = randn(n, m)
Y = A*Ω
if twopass
Q = qr!(Y).Q *Matrix(I,n,m)
T = Q'* A * Q
else
Q = qr(Y).Q *Matrix(I,n,m)
T = (Q'* Y) / ( Q'* Ω)
end
λ, S = eigen(T)
U = Q*S'if reconst
Λ =Diagonal(λ)
return U*Λ*U'elsereturn U, λ
endend
using LinearAlgebra
using Plots
using Statistics
import FFTW: plan_r2r!, R2HC,r2rFFTWPlan
"""We cited srft functions from [LowRankApprox library](https://github.com/JuliaMatrices/LowRankApprox.jl)"""functionsrft_apply!(
y::AbstractVecOrMat{T}, X::AbstractMatrix{T}, idx::AbstractVector,
r2rplan!::r2rFFTWPlan) whereT<:Real
l, m = size(X)
n = l*m
k = length(idx)
mul!(X, r2rplan!, X)
wn = exp(-2im*pi/n)
wm = exp(-2im*pi/m)
nnyq = div(n, 2)
cnyq = div(l, 2)
i =1@inboundswhile i <= k
idx_ = idx[i] -1
row = fld(idx_, l) +1
col = rem(idx_, l) +1
w = wm^(row -1)*wn^(col -1)
# find indices of real/imag parts
col_ = col -1
cswap = col_ > cnyq
ia = cswap ? l - col_ : col_
ib = col_ >0? l - ia :0# initialze next entry to fill
y[i] =0
s = one(T)
# compute only one entry if purely real or no more spaceif in ==0|| in == nnyq || i == k
for j =1:m
a = X[ia+1,j]
b = ib ==0|| ib == ia ? zero(T) : X[ib+1,j]
b = cswap ?-b : b
y[i] += real(s*(a + b*im))
s *= w
end# else compute one entry each for real/imag partselse
y[i+1] =0for j =1:m
a = X[ia+1,j]
b = ib ==0|| ib == ia ? zero(T) : X[ib+1,j]
b = cswap ?-b : b
z = s*(a + b*im)
y[i ] += real(z)
y[i+1] += imag(z)
s *= w
end
i +=1end
i +=1endendfunctionsrft_reshape!(X::AbstractMatrix, d::AbstractVector, x::AbstractVecOrMat)
l, m = size(X)
i =0@inboundsfor j =1:l, k=1:m
i +=1
X[j,k] = d[i] * x[i]
endendfunctionsrft_rand(::Type{T},n::Integer) whereT<:Real
x = rand(n)
@simdfor i =1:n
@inbounds x[i] =2*(x[i] >0.5) -1end
x
endfunctionsrft_init(::Type{T}, n::Integer, k::Integer) whereT<:Real
l = k
while n % l >0
l -=1end
m = div(n,l)
X =Array{T}(undef, l, m)
d = srft_rand(T,n)
idx = rand(1:n,k)
r2rplan!= plan_r2r!(X, R2HC, 1)
X, d, idx, r2rplan!end"""Get a product between m \times n matrix 'A' and 'n \times k` srft."""functionget_Y(A::AbstractMatrix{T}, k) whereT
m, n = size(A)
Y =Matrix{Float64}(undef,m,k)
X, d, idx, fftplan!= srft_init(T, n, k)
for i=1:m
srft_reshape!(X, d, view(A,i,:))
srft_apply!(view(Y,i,:),X,idx,fftplan!)
endreturn Y
end"""Randomized eigenvalue decomposition via Nystrom Method.See Fig 6 in the [original paper](https://arxiv.org/abs/1607.01649)or See Algorithm 5.5 in the [original paper](https://epubs.siam.org/doi/10.1137/090771806)This method is available for only a positive definite matrix.# Aruguments- 'A' : input positive definite matrix- 'k' : target rank, number of wanted eigenvalues- 'p' : over-sampling parameter, it should be 10 or 2k.- 'use_srft' : if ture, use subsampled Fourier transformation.- 'reconst' : if ture, the output is reconstracted matrix which approximates 'A'example: # make a positive definite matrix `A`. n = 5000; m = 25000; x = randn(m,n) demean_x = x .- mean(x, dims=1) A = demean_x'*demean_x ./(m-1) # run evdnys lowrank_mtx = evdnys(A,10, reconst=true)"""functionevdnys(A::Symmetric, k::Int;p=10, use_srft=false, reconst=false)
n, n = size(A)
if use_srft
Y = get_Y(A,k+p)
else
G = randn(n, k+p)
Y = A * G
end
Q = qr(Y).Q*Matrix(I,n,k+p)
B1 = A*Q
B2 = Q'*B1
C = cholesky(Symmetric(B2))
F = B1 * inv(C.U)
U, Σ, _ = svd(F)
if reconst
return U*diagm(Σ.^2)*U'elsereturn U, Σ.^2endend"""Randomized eigenvalue decomposition proposed by N.halko et al.See Algorithm 5.6. in the[original paper](https://epubs.siam.org/doi/10.1137/090771806).This method is effective matrices with decaying eigenvalues.# Aruguments- 'A' : input positive definite matrix- 'r' : target rank, number of wanted eigenvalues- 'p' : over-sampling parameter, it should be 10 or 2k.- 'use_srft' : if ture, use subsampled Fourier transformation.- 'reconst' : if ture, the output is reconstracted matrix which approximates 'A'example: # make a matrix with decaying eigenvalues n = 1500; A = rand(n,n); B = zeros(n,n) e, v = eigen(A) for i in 1:n B += e[i] * v[:,i] * v[:,i]' * (i>n-100 ? 1 : 1e-3) end # run reigen lowrank_mtx = reigen(A, 10, reconst=true)"""functionreigen(A, r ;p=10, twopass=false, use_srft=false, reconst=false)
n = size(A)[1]
m = r + p
if use_srft
Y = get_Y(A,m)
else
Ω = randn(n, m)
Y = A*Ω
end
Q = qr!(Y).Q *Matrix(I,n,m)
if twopass
T = Q'* A * Q
elseif use_srft
T = (Q'* Y) * ( (get_Y(Q',m))\I)
else
T = (Q'* Y) * ( (Q'* Ω)\I)
endend
λ, S = eigen(T)
U = Q*S'if reconst
Λ =Diagonal(λ)
return U*Λ*U'elsereturn U, λ
endend
前に実装したREDは固有値を大きい順にr個だけ高速に計算できましたが,固有値が減衰していない行列については,(Fノルムで評価する低ランク近似はうまくできても)固有値の近似がよくないアルゴリズムでした.今回のRED via Nystrom Methodは入力が正定値対称行列に縛られますが,高速にかつより正確に固有値を大きい順に求めることができます.
とくに困ったところはなく,半日くらいで順調に実装できました.
using LinearAlgebra
functionevdnys(A::Symmetric, k::Int;p=10)
n, n = size(A)
G = randn(n, k+p)
Y = A * G
Q = qr(Y).Q*Matrix(I,n,k+p)
B1 = A*Q
B2 = Q'*B1
C = cholesky(Symmetric(B2))
F = B1 * inv(C.U)
U, Σ, _ = svd(F)
#reconstract is U*diagm(Σ.^2)*U'return U, Σ.^2end
using Statistics
m =50
n =100
x = randn(n,m)
demean_x = x .- mean(x, dims=1)
A = demean_x'*demean_x ./(n-1)
isposdef(A) #true
比較のために前回実装した,EVDを用意しておきます.
functionreigen(A,r;p=10, twopass=false)
n = size(A)[1]
m = r + p
Ω = randn(n, m)
n, m = size(Ω)
Y = A*Ω
if twopass
Q = qr!(Y).Q *Matrix(I,n,m)
T = Q'* A * Q
else
Q = qr(Y).Q *Matrix(I,n,m)
T = (Q'* Y) * ( (Q'* Ω)\I)
end
λ, S = eigen(T)
Λ =Diagonal(λ)
U = Q*S'return U, λ
end