物理学徒が機械学習に入門した軌跡
修士課程までディラック電子系の理論物理をやってました.そのまま博士課程に進学することも考えましたが,色々考えて民間に就職して,深層学習を使ったコンピュタービジョンの研究をしました.2年後,会社を辞めて情報系の博士課程に編入しました.先日,友人に,今まで機械学習をどう勉強したか細かく教えてほしいと聞かれたので,機械学習何も分からん状態から機械学習をどう勉強したかを振り返りました.他の人にも役に立つかもしれないと思って,ちょっと肉付けして,公開することにしました.
「物理学徒が機械学習に入門するなら,こうするべきだ」と言うつもりは全くなくて,あくまで自分がどういう順番で勉強をしてきたのか,というメモのようなものです.凄まじいスピードで進歩する深層学習に関しては,以下に紹介した文献の一部が既に時代遅れになっているかもしれません.前提として,機械学習界隈に飛び込んだ時のスペックは,
プログラミングは,ごく小規模な実験のためにCとFortranでやったことがある程度.
Pythonは触ったこともない.
GPUが何かも説明できない.
微積分,線形代数をゴリゴリ使って物理の論文を数本書いたけど,関数解析とか確率解析とか幾何とかは全然分からない.ベイズ統計も知らない.
でした.
就職前
どうやら理論物理をやっている人は機械学習領域に需要があるらしいということを知り,そもそも機械学習とは何ぞやと思い,手に取ったのが「機械学習と深層学習」でした.当時はCとFortranしか書いたことがなかったのでサンプルコードがCで書かれているこの本には助かりました.簡単な数学が分かって、C言語が読めれば前半は誰でも分かるようになっています。「Q学習」「帰納学習」「遺伝的アルゴリズム」あたりを俯瞰するにはとてもよい本だったと思います。サンプルコードが汚い,という批判があるみたいですが,私にはどう汚いのかは分からなかったです.最近はサンプルコードがPython版も出版されたようです.

1年目春
どうやらディープラーニングというのものが産業応用されまくっているという噂を聞いて,ディープを勉強しようと思いました.初めに読んだ本が瀧の深層学習でした.Amazonの辛口のレビューが目立ちますが,私は良い本だと思います.自己符号化器の活性化関数を恒等関数にすると主成分分析になるみたいな基本的だけれども大事な話がちゃんと丁寧にかいてあるのはとても良いと思います.確かに未定義で記号を使ったり,表記ゆれがあったり,おびただしい量の誤植があったりしますが,数式をちゃんとフォローして理解したい人にとっては最適な本だと思います.一部,テクニカルな内容があったりするので,全部を完璧に理解する必要はないと思います.最近,ボルツマンマシンに関する研究をしてますが,この本の10章をよく参照します.著者が素粒子物理出身ということもあり,物理畑から来た人とは親和性がある本と思います.

イルカ本も評価が高かったので読んでみました.こちらも役に立ちました.イルカ本と瀧本の違いですが,瀧本の方が丁寧で概念的な説明も多く数式で説明されています.イルカ本は前半が丁寧ですがRNN以降の説明が良く分からないです.

どうやら仕事をするためには,Pythonを勉強しないといけないらしい,ということに気が付いたので,「詳細! Python 3 入門ノート」を勤務時間中に写経しました.3日もかからなかった気がします.Pythonがかける(嘘)ようになった私は「ゼロから作るDeep Learning」を読み始めます.初オライリー本でした.行列の微分の定義に戸惑った記憶があります.ライブラリは自分で作ったものを使おう!と謎の野心がありましたが,CNNあたりの章まで読んで気が変わった私は Chainerの環境構築を始めたのでした.最近は,自然言語処理編やフレームワーク編もあるみたいですね.


この頃,生成モデルがあちこちで大活躍しており,感動した私はVAEとかβ-VAEの論文を読み始めます.つけ焼き刃の知識で最新の論文が読めることにちょっと感動しました.あと,disentanglementという言葉が出てきたのはちょっと物理勢として嬉しかった記憶があります.
以上が,入社3か月くらいかけて読んだ本だったと思います.7時半に会社にいって勉強して,終業後と土日は近くの図書館でカリカリ勉強してました.ぜんぜん畑違いの物理学からこの分野に来たので,周りの強い人に追いつこうとすごく焦っていた記憶があります.それと,linuxが全然分からなくて,周りの情報系出身の人たちに対してすごい劣等感を感じていました.みんながbashの話をしているのに,私だけbashが何か分からなくてとてもつらかったです.Chainerのドキュメントを読んで分からないことを先輩に質問したら,「なんでコード読まないの?バカなの?」と言われてすごく落ち込んだりしました(そもそも,ドキュメントを読んで分からない時にコードを見に行く発想がなかった.どうせ当時は読めなかったし...).
1年目夏
会社ではGoodfellowを輪読しました.個人的にはあまり好きな本ではないのですが,周りの人は絶賛してたので人によっては役に立つんだと思います.Goodfellow本には地味に役に立つpracticalな話題が多いようで,深層学習を実際に活用している人が読むと学びが多いのかもしれません.初めに読む本ではなかったかなと思います.英語版は無料で公開されてます.

いざ開発をはじめるとディープに突っ込んでばかりで,もう少し古典的な手法を身に着けたいと思った私は,須山ベイズを読み始めます.行間を全部埋めて楽しんでました.5章にある線形次元削減とかはPythonで実装したりして遊んでました.

あとは,いまさらながら機械学習の評価の方法をちゃんと知っておこうということで,中川機械学習の1章を精読したら面白くてそのまま完読しました.基本が詰まっててすごくよかったです.時代に流されずに基本的なことをちゃんと抑えるには中川機械学習か,はじパタのどちらかをちゃんと読めばいいと思います.私は,はじパタは部分的にしか読んでいませんが,どちらもすぐれた入門書と思います.


1年目秋・冬
この頃は業務が忙しくて,スラスラ読める本ばかりに手を出すようになります.
先輩にコードが汚すぎると言われ,リーダブルコードを読んだ気がします.会社で「音楽の趣味でもあるの?」と言われた思い出.大事なことがたくさん書いてあるけど,実践できるようになったかは微妙です.コードを書くなら読んで損はないと思います.続けて,前処理が大事だと言われたので,「機械学習のための特徴量エンジニアリング」を読んだ気がします.スラスラ読めて楽しかった.


ディープについては大量の論文積読を横に,「イラストで学ぶディープラーニング 第二版」を読み始めました.タイトルからは信じられないくらい立派な本と思います.GANとかYOLOとかResNetとか当時知りたかったいろんなトピックが俯瞰できて良かったです.

2年目春・夏
もっといろいろ使える技を増やそうと,「ガウス過程と機械学習」に手を出してしまいます.これがめちゃくちゃ面白いかったのです.GPLVMとか自分で実装して,社内勉強会で発表したりしたんですけど,「計算量多いし,ディープで良くね?何に使えるん?」みたいな微妙な反応で悲しかった思い出.この本の第三章のコラムに興味を惹かれて,NNとGPの関係に関する論文とかを読み始めます(仕事には全く役に立たなかった).NNとGPの関係に感動した私は社内勉強会で発表するんですが,「高尚な発表ありがとうございました」と言われてで質疑が盛り上がならなったのが悲しかったです.この頃,機械学習のアプリケーションより,もうちょっと数理に根差した研究の方が面白いなと気が付いてしまう.

ノンパラ手法に興味がわき,「続 わかりやすいパターン認識 教師なし学習入門」の9,11,12章をガチ読みしました.この本のタイトルからは考えられないくらい重たかったです.ガンマ関数とかなり深い友情が結ばれたと思います.この辺を興味もって,自分で実装しようとしたんですけど,階乗がすぐにオーバーフローしちゃってうまくいかなかった思い出があります.この本は,難しいことをかなり分かりやすく説明してくれている良書ですが、後半の混合ディリクレ過程が相当ヘビーだから、覚悟して読み進めないと余裕で挫折すると思います.大変でした.ところどころ佐藤先生のノンパラメトリックベイズも参照しました.そういえば,1年目に他社の特許調査で出てきた「中華レストラン過程」という確率過程がなんだったのかをこの頃理解できてうれしかったです.「インド料理過程」があるのかとか興奮してました.(面白いネーミングですよね)


このころ,体調を崩して入院してて,彼女が見舞い品に「ディープラーニングと物理学」を持ってきました(本当に私の彼女はセンスが良い).あんまりちゃんと読めてないけど,物理と機械学習もいいなぁとか思う.

2年目秋以降
コンピュータビジョンの諸々の理解のためには,MLP赤本の画像認識を辞書的に使っていました.

確か,須山ベイズ深層学習とか読んでた気がします.途中まで読んだのですが,いつのまにか積読になってしまいました.

この頃は,業務の方はなかなか順調だったのですが,「ディープラーニングに突っ込んだらうまくできちゃった」っていうのが退屈に感じていました(所望のタスクをDLのタスクとして定式化したら解けてしまった).そんな感じで諸々を勉強しても全然会社での業務に活かせない(活かす能力が私にはなかった)ことへのフラストレーションがたまり,退職D進の覚悟を決め,情報幾何を勉強したり,博士でやる研究の準備をしてました.会社帰りに,博士課程でお世話になる先生とディスカッションしたり,有休をとってボスの論文を精読してたりしました.EMアルゴリズムの情報幾何的な解釈(emアルゴリズム)とかすごいなと思った記憶があります.
最後に
PRMLはどうなの?ってよく聞かれます.つまみ食いしかしてないですが,私にとってはあれは良い本です.よく参照しています(英語版は深刻な誤植があるらしいので,日本語版がよいらしい?)
あと,物理学徒は体系的に学問を勉強する訓練をしているので,「本で勉強する」ということに拘りがちな気がします.ポイントを押さえたら,そんなに真剣に本を読まずに,論文を読みまくるほうがよかったんじゃないかなと思ってます.それと,業務でMLをやるなら,言わずもがな多くの場合,理論よりもまず実装ができないとお話にならないので,その点に留意した方が良いと思います.DLフレームワークを使えるようにすることの優先順位は極めて高いと思います.
基本的には式の導出等は全部,手でフォローしていましたが,それが正しい勉強の方法だったかもよくわからないです.理論研究をするわけでなく,MLの社会実装のためにMLを勉強するなら,どの程度の粒度で理解する必要があるのか(或いは理解したいのか)に応じて,柔軟に理解の閾値を変えることも大事かなと思います.
Julia言語 二重確率行列分解
非負の対称行列を低ランク二重確率行列で近似するタスクに関する論文を読んだ. ここでいう近似は,KL情報量の意味での近似.
論文中のAlgorithm 1を実装した.
using LinearAlgebra function D_KL(A,B) (N, M) = size(A) dkl = 0.0 for i=1:N for j=1:M dkl += A[i,j] * log( A[i,j] / B[i,j] ) end end dkl -= sum(A) dkl += sum(B) return dkl end function getAhat(W) (N, r) = size(W) Ahat = zeros(N, N) for i = 1 : N for j = 1 : N term = 0 for k = 1 : r term += W[i,k] * W[j,k] / sum(W[:,k]) end Ahat[i,j] = term end end return Ahat end function DCD(A, W, r; alpha=1.0, cnt_max=20, verbose=true) N = size(A)[1] Z = zeros(N, N) cnt = 0 while true for i = 1 : N for j = 1 : N term = 0.0 for k = 1 : r term += W[i,k] * W[j,k] / sum( W[:,k] ) end Z[i, j] = term^(-1) * A[i, j] end end s = zeros(r) for k = 1 : r s[k] = sum( W[:, k] ) end nabla_m = zeros(N, r) nabla_p = zeros(N, r) ZW = Z*W WtZW = W'*Z*W for i = 1 : N for k = 1 : r nabla_m[i,k] = 2.0 * ZW[i,k] * 1.0 / s[k] + alpha * 1.0 / W[i,k] nabla_p[i,k] = WtZW[k,k] * 1.0 / ( s[k]^2 ) + 1.0 / W[i,k] end end a = zeros(N) b = zeros(N) term1 = W ./ nabla_p term2 = nabla_m ./ nabla_p for i = 1 : N a[i] = sum( term1[i,:] ) for l = 1:r b[i] += W[i,l] * term2[i,l] end end for i = 1 : N for k = 1 : r W[i,k] = W[i,k] * (nabla_m[i,k] * a[i] + 1.0 ) / (nabla_p[i,k] * a[i] + b[i]) end end if verbose Ahat = getAhat(W) dkl = D_KL(A, Ahat) println("cnt $cnt D_KL(A; Ahat) $dkl") end if cnt == cnt_max break end cnt += 1 end Ahat = getAhat(W) return W, Ahat end function main() n = 10 r = 2 cnt_max = 10 A = rand(n, n) A = Symmetric(A) A = n * A ./ sum(A) W_init = 0.5 * rand(n, r) W, Ahat = DCD(A, W_init, r, cnt_max=cnt_max) end main()
Julia言語 n個の空の配列を用意する方法.
emps = [ [], [], [], [], [] ]
みたいなのをつくりたい.そういう時は,
N = 5 emps = [[] for i=1:N]
とすればよい.
Zigzag graphene nanoribbons のエネルギー分散関係
大昔に研究で使っていたCのコードが発掘された.
グラフェンのジグザグナノリボンのバンド図を求めます。Nはユニットセル内の原子の数です。最近接のとびうつりのみを考えたタイトバインディングで計算しています。計算結果は/dataにdatファイルとして出力します。ハミルトニアンの対角化は,Lapackでやってます.
#include <stdio.h> #include <math.h> #include <complex.h> /**************************************************************** zigzagグラフェンナノリボンの計算。波数はky方向にのみ定義できる。 *****************************************************************/ int main(void) { int N =70; //ユニットセル内の原子数 FILE *saveband[N]; char bandname[50]; //エネルギーバンドを保存するファイル名 // Lapackに必要な変数 char jobz = 'V' ;// 固有ベクトルを計算する char uplo = 'U' ;// Aに上三角行列を格納 int n = N ;// 対角化する正方行列のサイズ double _Complex H[N*N] ;// 対角化する行列。対角化後は固有ベクトルが並ぶ double w[N] ;// 実固有値が小さい順に入る int lda = N ;// 対角化する正方行列のサイズ double _Complex work[6*N];// 対角化する際に使用するメモリ int lwork = 6*N ;// workの次元 double rwork[3*N-2] ;// 固定 int info ;// 成功すれば0、失敗すれば0以外を返す int i,j,p; double t=1; //transfer integral double a=1; //lattice constant double ky,kx; //wave vector kx=0 double fin=100; //計算の細かさ double V=0.0; //ユニットセル内の2つの原子のオンサイトポテンシャルの差 //保存するファイル名を決定する。 for(j=0;j<N;j++){ sprintf(bandname,"./data/band%d.dat",j); saveband[j] = fopen(bandname,"w"); } //各kyについてハミルトニアンを構成する for( p=-fin ; p<fin ; p++){ ky = 3.14*p/fin; for(i=0;i<N*N;i++){ H[i]=0.0; } for(j=0;j<N;j++){ if(2*j*(N+1) < N*N) H[2*j*(N+1)] = V ; if(2*j*(N+1)-1 > 0 && 2*j*(N+1) < N*N ) H[2*j*(N+1)-1] = t ; if(2*j*(N+1)+1 < N*N) H[2*j*(N+1)+1] = 2*t*cos(a*ky/2.0) ; if((2*j+1)*(N+1) < N*N) H[(2*j+1)*(N+1)] = -V; if((2*j+1)*(N+1)-1 > 0 && (2*j+1)*(N+1)-1 < N*N ) H[(2*j+1)*(N+1)-1] = 2*t*cos(a*ky/2.0) ; if((2*j+1)*(N+1)+1 < N*N) H[(2*j+1)*(N+1)+1] = t; } zheev_( &jobz, &uplo, &n, H, &lda, w, work, &lwork, rwork, &info ); for(j=0;j<N;j++){ fprintf(saveband[j],"%f\t%f\n",ky,w[j]); } } for(j=0;j<N;j++){ fclose(saveband[j]); } return 0; }
N=70の計算結果をgnuplotっでプロットさせたものです。横軸は波数、縦軸はエネルギー(eV)を表しています
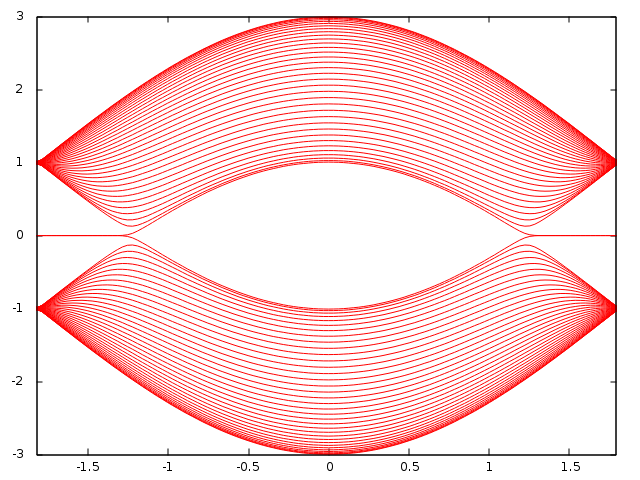
Fortran90 Hofstadter's butterfly.六方格子系に垂直磁場.
六方格子系に垂直に磁場を与えることでHofstadter's butterflyが現れる. 昔かいたFortranコードを発掘したのでアップロード. 自然界に現れるフラクタル構造って良いですよね. ちなみに,Hofstadter's butterflyは六方格子系以外の系に垂直磁場を与えてもみられます.
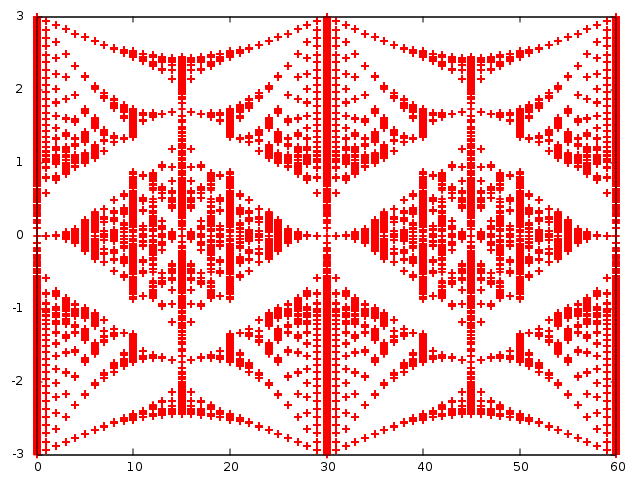
program zheevtest implicit none integer,parameter :: d=60 integer,parameter :: N = 2*d*d !対角化したい行列の次元 integer :: lda,lwork,info character :: jobz,uplo complex(8),dimension(n,n) :: H,work real(8),dimension(n) :: rwork,w real(8) :: t,onsite,alpha,beta,gamma,delta,phi1,phi2,B,x1,x2,Pi integer :: i,j,p,q,r,s,x,y,u,v,sgn1,sgn2,np interface function chr(p,q) implicit none integer :: chr integer :: p,q end function chr function trans(p,q,sgn) implicit none real :: trans integer,intent(in) :: p,q,sgn end function trans end interface jobz='N' !Nで固有値のみ計算。Vで固有ベクトルも計算 uplo='U' ; lda=n ; lwork=2*n-1 Pi=3.14159265359 t=-1.0d0 open(17,file="zheev.txt", status="replace") Do np=0,d write(*,*) np B=8.0*Pi*np/(3.0d0*sqrt(3.0)*d*1.0d0) Do x=0,d-1 Do y=0,d-1 Do sgn1=1,2 Do u=0,d-1 Do v=0,d-1 Do sgn2=1,2 x1=3.0*(x+y)/2.0 x2=3.0*(x+y)/2.0+1.0 phi1=sqrt(3.0)*B*(x1-1.0/4.0)/2.0 phi2=sqrt(3.0)*B*(x2+1.0/4.0)/2.0 alpha=cos(phi1)*chr(sgn1,1)*chr(x,u)*chr(y-1,v)*chr(2,sgn2)+cos(phi1)*chr(sgn1,1)*chr(x-1,u)*chr(y,v)*chr(2,sgn2)+chr(sgn1,1)*chr(x,u)*chr(y,v)*chr(2,sgn2) beta=cos(phi2)*chr(sgn1,2)*chr(x,u)*chr(y+1,v)*chr(1,sgn2)+cos(phi2)*chr(sgn1,2)*chr(x+1,u)*chr(y,v)*chr(1,sgn2)+chr(sgn1,2)*chr(x,u)*chr(y,v)*chr(1,sgn2) gamma=sin(phi1)*chr(sgn1,1)*chr(x,u)*chr(y-1,v)*chr(2,sgn2)-sin(phi1)*chr(sgn1,1)*chr(x-1,u)*chr(y,v)*chr(2,sgn2) delta=-sin(phi2)*chr(sgn1,2)*chr(x,u)*chr(y+1,v)*chr(1,sgn2)+sin(phi2)*chr(sgn1,2)*chr(x+1,u)*chr(y,v)*chr(1,sgn2) onsite=chr(sgn1,1)*chr(x,u)*chr(y,v)*chr(1,sgn2) - chr(sgn1,2)*chr(x,u)*chr(y,v)*chr(2,sgn2) H( d*d*(sgn1-1)+x*d+y+1 ,d*d*(sgn2-1)+u*d+v+1 )= cmplx(t*(alpha+beta)+0*onsite,t*(gamma+delta)) End Do End Do End Do End Do End Do End Do call zheev ( jobz , uplo , n , H, lda, w, work, lwork,rwork,info) Do p=1,N write(17,*) np,w(p) End Do End Do close(17) end program zheevtest function chr(p,q) implicit none integer :: chr integer,intent(in) :: p,q integer :: d if(p==q .or. p==q+60 .or. p==q-60 ) then chr=1 else chr=0 end if return end function chr function trans(p,q,sgn) implicit none integer :: trans integer,intent(in)::p,q,sgn integer :: d d=60 if(sgn==1) trans = p*d+q+1 if(sgn==2) trans = d*d+p*d+q+1 return end function trans
出力されるzheev.txtをgnuplotでプロットした。横軸が磁場,縦軸が許されるエネルギー準位。周期境界条件により許される磁場は離散的になる.
数理科学 2020年 11 月号 情報幾何学の探求を読んだ.
すっごい勉強になった.自分の専門分野もろかぶりだった. 情報幾何と機械学習あたりやっている人にとっては役に立つと思う.
特に印象に残ってるのは次の3つ.
江口真透:情報幾何学入門
2.目的変数にガウス分布を仮定して最尤推定するとKL情報量の三平方の定理
が自然に出てくる話.3のロバスト性のコメントとか面白い.直近でγダイバージェンスでNMFとかやってたのでかなり整理された.三平方の定理を中心にして幾何を整理するの,自然で分かりやすい.
駒木文保:Bayes統計の情報幾何
事前分布を雑に決めると,パラメータ変換に対し不変じゃなくて嬉しくない.そこでJeffreysの事前分布(パラメータ空間の体積みたいなもの)を採用しましょという内容.プロパーという性質を満たす事前分布に基づいた予測密度が許容的になる話など大変勉強になった.自分が考案したモデルのパラメータ空間の体積が運よく解析的に求まったが,何が嬉しいのか分からなかった.なので,長らく,パラメータ空間の体積の意味を知りたかった.そこでたまたまこの記事を見かけて,目から鱗.8節に,低ランク行列の集合の話が1行だけ書いてあるがもっと詳しく知りたい...
村田昇:機械学習における確率的推測
そもそも機械学習で確率分布を考えるのなぜか,に始まり,アルゴリズムを幾何的に捉えるとどう嬉しいのかを具体的に紹介してくれている.相変わらずイラストが多くて理解が進む(情報理論の基礎もsketchが多くて助かった).emアルゴリズムやboostingの説明が直感的に理解できる.勉強になったを通り越して,私の研究を進めるのに役に立った.
他にも深層学習の数理に関する記述も多くあったし,情報幾何のもっと基礎的なトピックもあった.量子情報幾何の話もあった.NTKと情報幾何に関心がある人は読んでみたらよいと思う.最近のトピックも載っていてよかった.
日本語で書かれた情報幾何に関する文献は少ないよね.(まぁ英語読めばいいんですが)

数理科学つながりでいうと,2018年の8月号にも機械学習や情報幾何に関するトピックが載っていた.こっちも勉強になった記憶がある.

Overleafで別のLatexファイルを参照refする方法.
Julia言語 非負テンソルをKL情報量でCP分解.CP-APRによる低ランク近似の実装
研究に必要だったので,Julia言語でこの論文のアルゴリズム3を実装した.「KL情報量でCP分解しましょう」って話だけど,中身はポアソン分布とかいろいろ書いてあってちゃんと読んでないから分からん.とりあえず非負のテンソルCP分解の手法の一つ.
Matlabではcp_arpコマンドですぐに呼び出せるらしい.
評価用に2つのテンソル間のKLダイバージェンスを求める関数を用意しておく.この関数はCP-APR本体では使わない.0 log 0 = 0 としておこう.
function DKL(P, Q) tensor_shape = size(P) dkl = 0.0 for idx in CartesianIndices(tensor_shape) if P[idx] < 1.0e-8 continue end if Q[idx] < 1.0e-8 continue end dkl += P[idx] * log( P[idx] / Q[idx] ) end return dkl - sum(P) + sum(Q) end
次に初期テンソルMを決める関数と,Sを更新する関数を用意しておく.Mの決め方は6.1.節を参照にしたけど,まぁ謎.
function get_M(I, N, R) A = [] for i = 1 : N a = rand(I[i], R) for j = 1:R coin = rand() if coin < (1.0 / R) a[j] = 100*rand() else a[j] = rand() end end for r = 1 : R a[:,r] = normalize(a[:,r],1) end push!(A, a) end lamb = rand(R) return lamb, A end function getS(k, In, R, An, Phin, kap, kaptol) S = zeros(In, R) if k == 1 return S else for i = 1 : In for r = 1 : R if An[i,r] < kaptol && Phin[i,r] > 1.0 S[i, r] = kap else S[i, r] = 0.0 end end end return S end end
次に本体をスクラッチ.TensorToolboxとか,TensorDecompositionsとか便利ですね.特にテンソルのKhatri–Rao productがTensorDecompositionsにあるのは便利でした.(LinearAlgebraのkronを繰り返せば同じことできるけど...)
入力テンソルXのCPランクをRにする関数.RはIntね.分解するだけが目的なら#reconstract以降は不要.
using LinearAlgebra using TensorDecompositions using TensorToolbox using InvertedIndices function CPARP(X , R ; kmax = 600, lmax = 10, tau = 1.0e-1, kap = 0.1, kaptol = 1.0e-3, epsilon = 1.0E-10 ) I = size(X) N = ndims(X) lamb, A = get_M(I, N, R) #A[i] \in R^{I[i] \times R} Phi = [] for n = 1 : N push!(Phi, rand(I[n], R)) end S = undef for k = 1 : kmax isConverged = true for n = 1 : N S = getS(k, I[n], R, A[n], Phi[n], kap, kaptol) B = (A[n]+S) * diagm( vec(lamb) ) PI = TensorDecompositions.khatrirao( reverse(A[Not(n)]) )' for l = 1:lmax Phi[n] = ( tenmat(X,n) ./ max.(B*PI,epsilon) ) * PI' if sum(abs.( min.(B, ones(size(Phi[n])) - Phi[n]) )) < tau break end isConverged = false B .= B .* Phi[n] end lamb = ones(1, size(B)[1]) * B A[n] = B * diagm( vec( 1 ./ lamb ) ) end if isConverged == true break end if k == kmax println("NOT CONVERGE k=$k") end end #reconstract G = zeros( fill(R, N)... ) for i = 1:R idx = fill(i, N) G[idx...] = lamb[i] end Y = ttm(G, A[1], 1) for n = 2:N Y = ttm(Y, A[n], n) end return Y end
試しに20×20×20のテンソルを低CPランクで近似してみる.
X = rand(20,20,20) Rs = [20, 17, 13, 10, 8, 5, 4, 3, 2, 1] for R in Rs Y = CPARP(X, R) println("R=$R ", "\t LS=", norm(X-Y), "\tKL=", DKL(X, Y) ) end
順調にLSエラーとKLエラーが上がっていくのが分かる.(CPランクが低いテンソルの表現力が低いという意味)
R=20 LS=22.880251175094255 KL=606.339285365445 R=17 LS=23.234143014881077 KL=624.7517055938652 R=13 LS=23.750102851245273 KL=653.4094801796946 R=10 LS=24.248429669696232 KL=679.6102072187259 R=8 LS=24.540291085977568 KL=695.6061065373501 R=5 LS=25.012954092190817 KL=721.7526514489091 R=4 LS=25.194662960281825 KL=731.3447268180694 R=3 LS=25.3753714333728 KL=740.7357057303489 R=2 LS=25.53270583385743 KL=748.5909542140225 R=1 LS=25.69656543115171 KL=756.886141185732
入力テンソルを大きくしたり,Rを大きくしたりすると,収束しなくなったりするので,うまい具合にハイパラをチューニングする必要がある. tau と kap を調節するとうまくいくことが多い.論文じゃいろいろ考察があるけどlmaxはどう設定したらよいかよくわからん.
Julia言語 niiファイルを読み込む
fMRIの出力がniiファイルらしい.良く分からないが,using NIfTI で開ける.
using NIfTI ni = niread("hogehoge.nii") ni = niread("foo.nii.gz")
でOK.普通の配列にしたかったら convert(Array{Float64}, ni) でOK.
Julia言語 衛星データgeotifファイルを読み取る
NASAのページからgeotifファイルをダウンロードできるんだけど,juliaでどう開けばよいか分からなかった.
色々調べたけど,多分これが一番良い.
using GeoArrays geoarray = GeoArrays.read("hogehoge.tif")
座標をとりだしたかったら,
coords(geoarray )としたらよい.
Julia言語 pngを読み込んでarrayに変換する.
juliaで
using FileIO img = load("hogehoge.png")
したあとに,r,g,b要素を取り出したかったら,それぞれ
using Colors
r = red.(img)
g = green.(img)
b = blue.(img)
とする.ちなみにこのままだとr,g,bはそれぞれ
Array{N0f8,2} with eltype FixedPointNumbers.Normed{UInt8,8}
という謎の型をもっている.普通にarrayにしたかったら,
convert(Array{Float64}, blue.(a))
とすればよい.
Julia言語 テンソルの添え字集合をつくる
自然数nに対して,[n] = {1, 2, …, n} として,[I]×[J]×[K]が欲しい時ととかってあるじゃないですか.テンソルの添え字でloop作りたいときとか.そういうときは,IterToolsのproductを使うとよいことに気が付いた.
using IterTools I = 2 J = 3 K = 2 for idx in product(1:I, 1:J, 1:K) print(idx) end
これで
(1, 1, 1) (2, 1, 1) (1, 2, 1) (2, 2, 1) (1, 3, 1) (2, 3, 1) (1, 1, 2) (2, 1, 2) (1, 2, 2) (2, 2, 2) (1, 3, 2) (2, 3, 2)
を得る.もっと早く知りたかった.
強い人に
CartesianIndices((I,J,K))でできることも教わった.
博士をとるのに役立ちそうなものたち[随時更新]
(修士/博士/普通の)論文執筆の際にお願いしたいこと、その二
http://www.k2r.org/kenji/japanese-articles/ouistmmphd
人生いろいろ(30後半で研究者への道に飛び込んで40後半に博士取得)
How to go to U.S. graduate schools in mathematics
博士後期課程進学に興味をもつお茶大伊藤研究室関係者の皆さんへ
大学院の5年間を振り返る:自然言語処理の研究者を目指して(博士課程) - 貴殿より申請のありました
博士への長い道TM - 東京大学 計数工学専攻 (課程博士) の場合 (2002 年度版)
博士への長い道FAQ - 慶應大学理工学研究科の場合(1997年度版)
https://developers.cyberagent.co.jp/blog/archives/35214/
科研費
TOOLS
手書きの文字をTeXに変換してくれるツール
オンラインで無料で使えるLatex
AI関係
就職
私はこうやってGoogleに入った (Research Scientist編)
任期付き大学教員・研究者の苦悩と任期無し教員の考えとのギャップについて
転職エントリー(東大の博士課程・理研JRA→(株)リクルートのデータサイエンティスト)
アカデミアを目指そうとしている人に対する雑多なアドバイスと個人的意見
小松氏による「ファカルティー、グラント、フェローシップの応募書類の書き方」
Writing ノウハウ
Julia言語 L1ノルムでのテンソルランク1近似の解析解
3階のテンソルをL1ノルムの尺度で近似するランク1テンソルを見つけます,という論文を実装した.論文のタイトルにexact solutionがあるけど,L1ノルムの意味での最良1ランク近似をしてるわけではないので注意(かなり混乱した).
最近,L1が流行っているのかな.著者にお願いしてuploadしてもらったpythonコードとまったく同じ結果を返したので,このjulia実装は正しいと思う.私はgreedyのバージョンしか実装していないので,もっと速くする方法も論文を読めば載ってます(実装大変そうだからあきらめたけど,pythonコードを翻訳すればいけるかも?)
using TensorToolbox using LinearAlgebra using Arpack function exactL1(tensor) X = tenmat(tensor, 1) #mode-1 matricization (D, M, N) = size(tensor) B = vec(collect(Iterators.product(fill([-1,1],N)...))) numOfCandidates = 2^N metopt = 0 bopt = undef for n = 1:numOfCandidates b = collect(B[n]) Z = X * kron(b, Matrix(I, M, M)) sigmamax = svds(Z, nsv=1)[1].S[1] if sigmamax > metopt metopt = sigmamax bopt = b end end USV = svds( X*kron(bopt, Matrix(I,M,M)), nsv=1)[1] uopt = USV.U[:,1] vopt = USV.Vt[1,:] return uopt, vopt, bopt, metopt end
入力行列の復元は原論文に従って,こんな感じ.試しにランク1テンソルを入力にしてみると,エラーがとても小さくなることが確かめられた.
P = [1 2] Q = [2 3 4] R = [4 5 6 7] T = dropdims( ttt(ttt(P,Q),R) ) uopt,vopt,bopt,metopt = exactL1(T) T1 = zeros(2,3,4) for i = 1 : 4 T1[:,:,i] = ( uopt * uopt' ) * T[:, :, i] * ( vopt * vopt' ) end println( norm(T-T1) )
C++ 行列バランシング
行列バランシングと言えば,sinkhornですが,今回はこの論文を実装しました.
(論文では自然勾配法使ってますが,ここでは,1次までしか実装してないです)
#include <iostream> #include <Eigen/Dense> #include <vector> #include <cmath> #include <time.h> #include <cstdio> #include <fstream> using namespace std; using namespace Eigen; MatrixXd balance(MatrixXd& P, double lr){ int N = P.rows(); MatrixXd eta(N, N), theta(N, N); VectorXd eta_beta(N); // get eta_beta; for (int i = 0; i < N ; i++){ eta_beta( i ) = ( 1.0 * N - 1.0 * i ) / (1.0 * N); } // get theta of input // we need all element to update p in iteration. double sum; for (int i = 0; i < N; i++){ for(int j = 0; j < N; j++){ sum = 0.0; sum = log( P(i, j) ); if (0 < i) sum -= log( P( i-1, j) ); if (0 < j) sum -= log( P( i, j-1 ) ); if (0 < i and 0 < j) sum += log( P( i-1, j-1) ); theta(i, j) = sum; } } // get eta of input eta( 0, N - 1 ) = P.col( N - 1 ).sum(); eta( N - 1, 0 ) = P.row( N - 1 ).sum(); for (int i = 2; i < N; i++){ eta( 0, N - i ) = eta( 0, N - i + 1) + P.col( N - i ).sum(); eta( N - i, 0 ) = eta( N - i + 1,0 ) + P.row( N - i ).sum(); } int cnt = 0; while(true){ // e-projection for(int i = 0; i < N ; i++){ theta(i, 0) -= lr * ( eta(i, 0) - eta_beta( i ) ); theta(0, i) -= lr * ( eta(0, i) - eta_beta( i ) ); } // update prob by theta double logp_ij; for (int i = 0; i < N; i++){ for (int j = 0; j < N; j++){ logp_ij = 0.0; logp_ij = theta(i, j); if ( 0 < i ) logp_ij += log( P(i-1, j) ); if ( 0 < j ) logp_ij += log( P(i, j-1) ); if ( 0 < j and 0 < i ) logp_ij -= log( P(i-1, j-1) ); P(i, j) = exp( logp_ij ); } } // normalize P = P / P.sum(); // update eta by prob eta( 0, N - 1 ) = P.col( N - 1 ).sum(); eta( N - 1, 0 ) = P.row( N - 1 ).sum(); for (int i = 2; i < N; i++){ eta( 0, N - i ) = eta( 0, N - i + 1) + P.col( N - i ).sum(); eta( N - i, 0 ) = eta( N - i + 1,0 ) + P.row( N - i ).sum(); } cnt += 1; if (cnt > 2000) break; } return P; } int main(){ double LO = 0.0; // minimu value of element of random matrix; double HI = 1.0; // maximu value of element of random matrix; double range = HI - LO; double lr = 0.1; int N = 25; // matrix dimenstion MatrixXd Q(N, N); // output matrix // producting random input matrix P MatrixXd P = MatrixXd::Random(N, N); P = (P + MatrixXd::Constant(N, N, 1.0))*range/2; P = (P + MatrixXd::Constant(N, N, LO)); /* P <<1,5,3,6, 9,5,5,6, 1,7,10,9, 2,3,1,4; */ P = P / P.sum(); cout << "input matrix" << endl << P << endl; Q = balance( P, lr ); cout << "output matrix" << endl << Q << endl; double rowsum,colsum; for(int i=0;i<N;i++){ colsum = Q.row(i).sum(); rowsum = Q.col(i).sum(); printf("%d colsum = %f \t rowsum = %f\n",i,colsum,rowsum); } }