Julia言語 文字列をfloatに変換
julia で string から float への変換は parse() を用いる.単にfloat("0.12")とかはダメ

Julia言語 ST-HOSVDによる低ランク近似
このスライドのp26, アルゴリズム2をJulia言語で実装しました.
https://mycourses.aalto.fi/pluginfile.php/1249889/mod_resource/content/1/Lecture6.pdf
素朴なHOSVDや,T-HOSVDより効率よく低ランク近似が実現できているらしいです. ArpackだとフルHOSVDができないので場合分けするのが悔しい....(そもそもArpackは疎行列を念頭に置いたライブラリっぽい.)
using TensorToolbox using LinearAlgebra using Arpack function STHOSVD(T, reqrank) N = ndims(T) tensor_shape = size(T) for i = 1 : N T_i = tenmat(T, i) if reqrank[i] == tensor_shape[i] USV = svd(T_i) else USV = svds(T_i; nsv=reqrank[i] )[1] end T = ttm( T, USV.U * USV.U', i) end return T end
この文献のアルゴリズム1なども参考.
Julia言語 Truncated HOSVDによる1ランク近似
Julia言語で,T-HOSVDによりテンソルランクを1にするアルゴリズムを実装しました. この論文のアルゴリズム3を実装しました.
using TensorToolbox using LinearAlgebra using Arpack function THOSVD(T) # Output is rank-1 tensor N = ndims(T) input_tensor_shape = size(T) u = [] for n=1:N # Matricization of tensor by mode n Tn = tenmat(T,n) # First left singula vector of Tn un = svds( Tn ; nsv=1 ).U[:, 1] push!(u, un) end U = ttt(u[1],u[2]) for n=3:N U = ttt(U, u[n]) end println(size(U)) lammda = innerprod(T, U) X = lammda .* U return X end T = [ 1 -1 0 1 3 im 0 1 ; 0.0 1 -im 1 1 0 2 -2im] T = matten(T, 1, [2,2,2,2]) X_THOSVD = THOSVD(T)
Julia言語 SVDによる低ランク近似
Julia でSVD をするときに,Lapackを使って
using LinearAlgebra n = 10 A = rand(n, n) svd(A)
としても良いのですが,これだとO(n3)必要ですね. ランクをrにするのに,完全なSVDをする必要はありません.Arpackのsvdsを使うべし.
using Arpack n = 10 r = 5 A = rand(n, n) svd = svds(A ; nsv=r, ritzvec=true)[1] Ar = svd.U * diagm(svd.S) * svd.Vt
で10×10行列Aの5ランク近似がO(n2 r)で手に入ります.
実際に時間はかってみるとこんな感じ.
Arpackのほうがだいぶはやいが,rが大きいときは,Lapackの方がはやいっぽい.
using LinearAlgebra using Arpack n = 2000 A = rand(n, n) @time svd(A); # 4.236471 seconds (12 allocations: 183.350 MiB, 3.53% gc time) r = 5 @time svds(A ; nsv=r, ritzvec=true)[1]; # 0.479803 seconds (1.35 k allocations: 840.125 KiB) r = 10 @time svds(A ; nsv=r, ritzvec=true)[1]; # 0.654874 seconds (1.78 k allocations: 1.237 MiB) r = 100 @time svds(A ; nsv=r, ritzvec=true)[1]; # 1.538005 seconds (3.57 k allocations: 11.446 MiB) r = 200 @time svds(A ; nsv=r, ritzvec=true)[1]; # 2.692379 seconds (5.21 k allocations: 23.644 MiB) r = 400 @time svds(A ; nsv=r, ritzvec=true)[1]; # 5.119713 seconds (7.29 k allocations: 50.736 MiB)
関連記事
Julia言語 np.squeezeはdropdimsを使う
pythonのnp.squeezeをjulia言語でやるなら,dropdimsを使うと良い.juliaにも昔は'squeeze'関数があったっぽいが,今は消えてしまった?
Julia言語 タプルを配列になおす
collectを使うと良いです.
tup = (1,2,3,4,5) ary = collect(tup)
これで配列arrayに直されます.
Julia言語 HOSVDによるタッカー低ランク近似
行列の低ランク近似がSVDによって実現されるように,テンソルの低(タッカー)ランク近似がHOSVDで実現できます.
なお,Eckart Youngの定理より,SVDがフロベニウスノルムの意味で最良低ランク近似を実現しますが,テンソルの場合はそのような保証はないと思います.
テンソルにおいては,タッカーランクとCPランクという異なるランクの定義が存在します.(以下,研究室のセミナーで用いた資料.間違ってたらゴメン)


記号×_nはモードn積です.モード積の定義はこちらを参考にすると良いと思います.
juliaでHOSVDがさくっとできないかいろいろ試してましたが,TensorToolboxを使うのが手っ取り早そうですね.例として3×3×3テンソルTをHOSVDによってタッカーランク(2,2,2)で近似するJuliaコードは以下.
using TensorToolbox function HOSVD(T, reqrank) X = hosvd(T, reqrank=reqrank) g = X.cten Us = X.fmat #X = ttm(g, [Us[1],Us[2],Us[3]],[1,2,3]) X = ttm(g, [Us...]) return X end T = rand(3,3,3) println("input tensor") display(T) X = HOSVD(T, [2,2,2]) println("\n\noutput tensor") display(X) println("\n\nerror") println(norm(X-T))
タッカーランクを[3,3,3]にすると,エラーが0になります.
X.cten でコアテンソルが取り出せて,X.fmat でスライドでいうところのU_1,U_2,…を取り出しています.
ttmの使い方はgithubに丁寧に載ってます.ttm(X, A, 2)がXとAのモード2積 X ×_2 A です.
ところで,この実装って Truncated HOSVD になっているのだろうか...
Julia言語 n階のテンソルを初期化する.
3×3×3のテンソルを用意したいときは,X = rand(3,3,3) みたいにするとおもいますが,階数が大きい時に X = rand(i1,i2,i3,i4, ..., ,in って手動で入力するのが大変だったので,i = [i1,i2,i3,…,in] を用意して
using TensorToolbox
X = diagt(i)
みたくしてたけど,どうもX = rand(i...) で良いらしい.... は splat演算子というらしく,ドキュメントにもちゃんと記述がある.
docs.julialang.org
n階のテンソルの初式化をするなら,
X = Array{Float64, n}(undef, i...)
のようにすればよいね.
中島伸一「変分ベイズ学習」の7章がとんでもなく勉強になった.
IBISに参加してみて,「行列分解の研究をしているの行列分解をあんまりよく理解していないな,確率的主成分分析でも勉強するか」と思い,中島変分ベイズの3-5,3-8,6章のほとんど,7章の全てを読んでみた.
須山ベイズを読み込んでいたので,スムーズに読めた.ベイズをやっていれば,繰り返し参照するであろう計算がかなり丁寧に整理されているので手元にあると便利だと思う.Notationもよく整理されていて読みやすかった.

変分ベイズの一般論
↓
応用例として行列分解モデル
↓
実は行列分解モデルって大域解が解析的に求まるので理論的な探求をしてみましょう(7章)
っていう展開が私的には凄く良かった.というか,行列分解モデルを変分ベイズで解こうとすると,大域解って求まるんですね,すごい.要は確率的行列分解は,SVDとコンシステントです,ってことだとは思うんだけど,全然知らなかったのでかなりワクワクして読んだ.この辺り,大事な補題の証明は載ってないけど,refがついているからフォローできるんじゃないかな(私はフォローしてない).アルゴリズムは私くらいのコーディングスキルの人間でも実装できるレベルで書いてある(実装してないけど).Juliaもくもく会とかで実装してみようかな.
他のベイズのアプリケーションの本を知らないので,比較できないけど,私のような初学者にとって,7章は驚きに満ちた章だった.普通の変分ベイズの大域解だけじゃなくて,経験変分ベイズの大域解までちゃんと載せるの,著者の情熱を感じるよね.
LDAに関する議論もたくさんあるのでもう少し読み込んでみるつもり.これから機械学習始めます,みたいな人にはおすすめできないけど,須山ベイズをやり切ったくらいの体力がある人はぜひ手に取ってみるといいと思う.本当に7章は勉強になった.他の章も,縮小カーネル回帰とか,協調フィルタリングとか,私の研究テーマ近傍の話もあって,とても有益だった.
ちなみに,須山ベイズはめっちゃ良い本なので,機械学習やる人なら絶対に読んだ方が良いです.須山ベイズの方は入門向けと思う.
Julia言語 行列要素ごとにexpする.
ただのメモです.
行列Aに対して,exp(A) とすると,行列指数関数が発動されてしまう.
element-wiseに演算をしたいときは,.を使う.
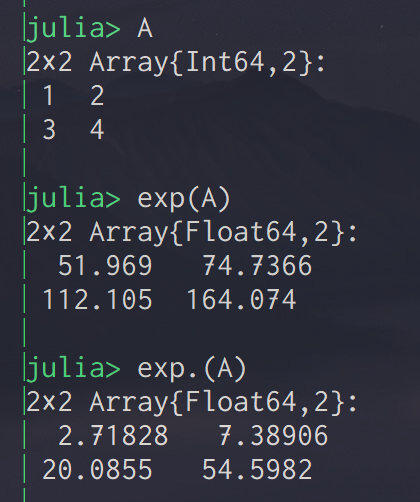
exp.(A)で各要素ごとにexpされる.
A*Bは行列毎の積だけど,A.*Bにすると,要素積になる.
原 啓介「線形性・固有値・テンソル」は行列代数を卒業して抽象的な線形代数に挑む人におすすめ.
とてもとても良かった. 物理で線形代数には慣れ親しんでいたはずだけど,いつの間にか私が物理の計算で使うのは線形代数ではなく行列演算になってしまっていて,多重線形性とテンソルの関係とかすっかり忘れてしまっていたので,リハビリとしてもとても良い運動になった..
固有値の計算とか,行列式の計算とか,そういうのに慣れていても,抽象的なベクトル空間の数学としての線形代数の知識が体系的にまとまっていない人に強くおすすめします.テンソルの話や,内積空間の議論も豊富で役に立ちました.
巷の低評価が謎過ぎる!非常に勉強になった.ストーリーがしっかりしていて,何が重要で何が本質なのかが明示的に書かれている.読みやすい.今後も何度も見直すと思う.
階数定理から線形写像の大切な性質が示せるくだりや、行列の積の定義が抽象的な議論から自然に出てくるくだりがとても勉強になった。4章も分かりやすい.線形写像の表現が行列であったように,多重線形写像の表現がテンソル,ふむふむ.(些細なこともしれないけど)双線形写像を線形性の言葉で調べるために,テンソル積を導入するとか,ちゃんと書いてあって本筋を見失わずに読めた.機械学習やってて,急にテンソルを扱うことになり,テンソル積の定義とかをググりながらつまみ食いしがちな私にとっては,とても役に立った本.

同著者の別の本も買ってみようかしら.
Python 極座標上に素数をプロット
楽しい動画だった.
練習がてら,任意の素数pに対して極座標(r, θ) = (p, p)の点をプロットするプログラムを作ってみた.
import numpy as np import matplotlib.pyplot as plt import math import time max_max_number = 100000 interval = 100 def get_prime_numbers(): start = time.time() prime_numbers = [2] for L in range(3, max_max_number): chk=True for L2 in prime_numbers: if L%L2 == 0:chk=False if chk==True:prime_numbers.append(L) prime_numbers = np.array(prime_numbers) return prime_numbers def converte_pn_coordinates(pns): converted_pns_x = [pn*math.cos(pn) for pn in pns] converted_pns_y = [pn*math.sin(pn) for pn in pns] return converted_pns_x, converted_pns_y def main(): print("getting prime_numbers...") prime_numbers = get_prime_numbers() print("converting polar coordinate...") converted_prime_numbers_x, converted_prime_numbers_y = converte_pn_coordinates(prime_numbers) for max_number in range(0, max_max_number, interval): num_plot_points = len(prime_numbers[prime_numbers < max_number]) x = converted_prime_numbers_x[:num_plot_points] y = converted_prime_numbers_y[:num_plot_points] max_prime_number = prime_numbers[num_plot_points] plt.figure(figsize=(5,5)) plt.scatter(x, y, s=0.5, c="red") plt.title("p < {}".format(max_number)) plt.axis("off") plt.xlim(-max_prime_number, +max_prime_number) plt.ylim(-max_prime_number, +max_prime_number) plt.savefig("save/{}.png".format(str(max_number).zfill(8))) plt.close() print("save/{}.png has been saved".format(str(max_number).zfill(8))) if __name__ == "__main__":[f:id:physics303:20201205224739p:plain] main()
学部1年生の時に,リーマン予想とか知らずに,素数の分布を調べようと,1から1000くらいまでの素数をあれこれプロットして規則性がないか調べてたなぁ(何も分からなかった)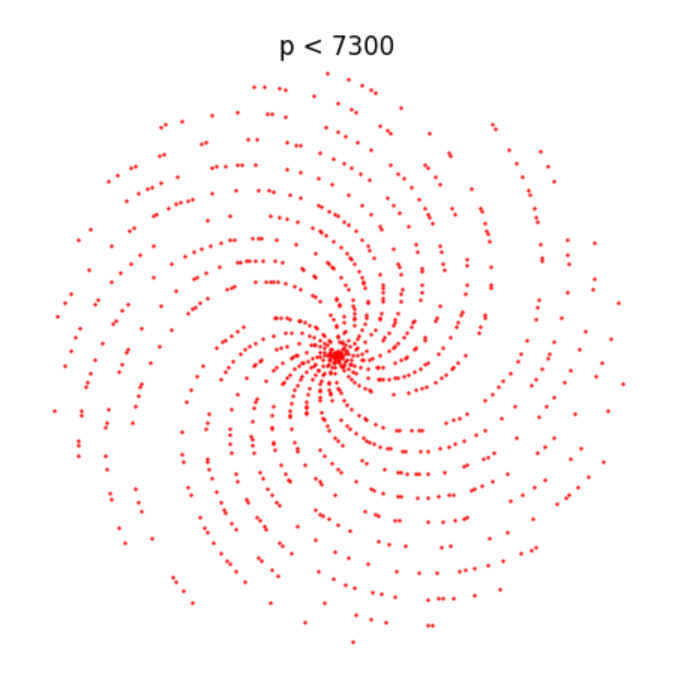
Python SVDによる低ランク近似
PythonでSVDで入力行列Aのランクをrankに落とすプログラム. ちなみに,C++バージョンはこっち.
import numpy as np import scipy as sp def SVD(A, rank): u, s, v = np.linalg.svd(A) ur = u[:, :rank] sr = np.matrix(sp.linalg.diagsvd(s[:rank], rank, rank)) vr = v[:rank, :] Rr = ur*sr*vr return Rr
ちなみにこのコードだと,O(n3)かかる.Arpack使うと,O(n2 r)でできるはず... scipy.sparse.linalg.svds を参考.(スパース行列じゃなくてもできる)
噂では,sklearn.decomposition.truncatedSVD も使えるようだ. 計算量をさらにO(n2 log r + r2 n)まで落とすこともできるようで,これはこちらの論文に載っている(らしい.私は読んでない)
SVDでrランク近似するの、普通にnumpy.linalg.svd使うとO(n^3)やん。
— ゆうだい.jl (@physics303) 2020年11月12日
でも噂では、O(n^2 r)でできるらしいじゃん。どうやるの?Juliaでも良い。既に実装されてるライブラリがあるはずだよね?#Julia言語
C++ eigenでランダム行列を作る
最小値LOから最大値HIの値を一様にとる連続分布で,N×Nの行列を作る方法.
#include <Eigen/Dense> #include <iostream> #include <cmath> using namespace Eigen; using namespace std; MatrixXd random_uniform_mtx(int N, double LO, double HI){ double range = HI - LO ; MatrixXd P = MatrixXd::Random(N, N); P = (P + MatrixXd::Constant(N, N, HI))*range/2; P = (P + MatrixXd::Constant(N, N, LO)); return P; }
Stack Overflow で見かけたコードだった気がするが,ぐぐっても見当たらなくなっていた...