各要素が適当な分布に従うテンソルをつくる.例えば,中心がmu, 分散がsigmaの一次元ガウス分布に各要素が従うD×M×Nテンソルをつくりたければ
using Distributions mu = 0 sigma = 5 D = 2 M = 3 N = 5 dist = Normal(mu, sigma) X = rand( dist, (D, M, N) )
とすればいい.
集合 B ={ b ∈ {±1}^N } を得たい! 僕が考えたのはこんな感じ.
using Combinatorics function main(N) B=[] for n=1:N combs = collect(combinations(1:N,n)) for comb in combs b = ones(N) for com in comb b[com] = -1 end push!(B,b) end end return B end B = main(5) display(B)
これを実行すれば
[1.0, 1.0, 1.0, 1.0, 1.0] [-1.0, 1.0, 1.0, 1.0, 1.0] [1.0, -1.0, 1.0, 1.0, 1.0] [1.0, 1.0, -1.0, 1.0, 1.0] [1.0, 1.0, 1.0, -1.0, 1.0] [1.0, 1.0, 1.0, 1.0, -1.0] [-1.0, -1.0, 1.0, 1.0, 1.0] [-1.0, 1.0, -1.0, 1.0, 1.0] [-1.0, 1.0, 1.0, -1.0, 1.0] [-1.0, 1.0, 1.0, 1.0, -1.0] [1.0, -1.0, -1.0, 1.0, 1.0] [1.0, -1.0, 1.0, -1.0, 1.0] [1.0, -1.0, 1.0, 1.0, -1.0] [1.0, 1.0, -1.0, -1.0, 1.0] [1.0, 1.0, -1.0, 1.0, -1.0] [1.0, 1.0, 1.0, -1.0, -1.0] [-1.0, -1.0, -1.0, 1.0, 1.0] [-1.0, -1.0, 1.0, -1.0, 1.0] [-1.0, -1.0, 1.0, 1.0, -1.0] [-1.0, 1.0, -1.0, -1.0, 1.0] [-1.0, 1.0, -1.0, 1.0, -1.0] [-1.0, 1.0, 1.0, -1.0, -1.0] [1.0, -1.0, -1.0, -1.0, 1.0] [1.0, -1.0, -1.0, 1.0, -1.0] [1.0, -1.0, 1.0, -1.0, -1.0] [1.0, 1.0, -1.0, -1.0, -1.0] [-1.0, -1.0, -1.0, -1.0, 1.0] [-1.0, -1.0, -1.0, 1.0, -1.0] [-1.0, -1.0, 1.0, -1.0, -1.0] [-1.0, 1.0, -1.0, -1.0, -1.0] [1.0, -1.0, -1.0, -1.0, -1.0] [-1.0, -1.0, -1.0, -1.0, -1.0]
となって,所望の集合Bを得る.
これで,めでたしめでたしなのだが,もっと良い方法を強い人に教えてもらった.
a = [-1, 1] B = vec(collect(Iterators.product(fill(a,4)...)))
これでも同じものが手に入る.Iteratorsを使いこなせるようになりたい.
また,他の強い人に,bit探索のノリでいけるんじゃないの?というコメントを貰いました.
for i in 0:2^N-1 ptn = digits(i, base=2, pad=N) println(ptn) end
所望のBにしたかったら,2倍して,1を引けばよい.これ,とても速い気がするんだけど,どうなんだろう.
そんなことせずに,無名関数でどうにかなることを知りました.
arr = [-1,1] for i in 0:2^N-1 ptn = digits(i, base=2, pad=N) println( (d -> arr[d+1]).(ptn) ) end
また,他の強い人によると,このように1行で済ませることもできるみたいです.
[[(-1)^parse(Int,string(i, base=2,pad=5)[k]) for k=1:5] for i=0:2^5-1 ]
また,他の強い人によると,map関数をうまく使えばもっとスマートのようです.
[map(x->2x-1, digits(i,base=2,pad=N)) for i in 0:2^(N)-1]
また,他の強い人によると,このようにもできるみたいです.
n = 4 [[(-1)^(i >> k & 1) for k in 0:n-1 ] for i in 1:2^n]
自分が勉強するのに役に立ったYoutubeで公開されている講義をどんどん追加していきます.
松本多様体の内容を(かなり端折りながらも)丁寧に追っていく授業です.理解が深まりました.面白かった.
確率過程論を測度論、積分論を前提にせずに授業してくれているありがたい授業.
まだ観てないが,代数についての講義っぽい.
まだ観てないが,代数についての講義っぽい.ガロア理論に追いつくには良いかも?
修士課程の時に何度も繰り返しみた講義です.ベリー位相や物性のトポロジカルな性質などが非常に良くまとまっています.私が修士の時は,この辺りは優れた日本語の教科書がなかったので,この講義にはかなり助けられました.
式変形チャンネル ゼロから始める群論2020
式変形チャンネル 群論シリーズ ~群の定義から準同型定理まで~
Masaki Koga [数学解説] 具体例で学ぶ代数学《群論》
AIcia Solid Project ブラックショールズ方程式への道 9講
ひとまずpythonにwandbをインストールする.
pip install wandb
次に,JuliaにPyCallをインストールする.
(@v1.5) pkg> add PyCall
wandbの公式ページでアカウントをつくる.適当なプロジェクトを作る. その語,Pythonでwandbを使うようにjuliaで
julia > using PyCall julia > wandb=pyimport("wandb") julia > wandb.init(project="(プロジェクト名)") julia > wandb.log( PyDict( 'epoch'=>1, 'loss'=>2) ) julia > wandb.log( PyDict( 'epoch'=>2, 'loss'=>3) ) julia > wandb.log( PyDict( 'epoch'=>3, 'loss'=>4) )
juliaを終了すると,logがアップロードされる模様.ブラウザでマイページを見てみると更新されているのが分かる.
julia で string から float への変換は parse() を用いる.単にfloat("0.12")とかはダメ

このスライドのp26, アルゴリズム2をJulia言語で実装しました.
https://mycourses.aalto.fi/pluginfile.php/1249889/mod_resource/content/1/Lecture6.pdf
素朴なHOSVDや,T-HOSVDより効率よく低ランク近似が実現できているらしいです. ArpackだとフルHOSVDができないので場合分けするのが悔しい....(そもそもArpackは疎行列を念頭に置いたライブラリっぽい.)
using TensorToolbox using LinearAlgebra using Arpack function STHOSVD(T, reqrank) N = ndims(T) tensor_shape = size(T) for i = 1 : N T_i = tenmat(T, i) if reqrank[i] == tensor_shape[i] USV = svd(T_i) else USV = svds(T_i; nsv=reqrank[i] )[1] end T = ttm( T, USV.U * USV.U', i) end return T end
この文献のアルゴリズム1なども参考.
Julia言語で,T-HOSVDによりテンソルランクを1にするアルゴリズムを実装しました. この論文のアルゴリズム3を実装しました.
using TensorToolbox using LinearAlgebra using Arpack function THOSVD(T) # Output is rank-1 tensor N = ndims(T) input_tensor_shape = size(T) u = [] for n=1:N # Matricization of tensor by mode n Tn = tenmat(T,n) # First left singula vector of Tn un = svds( Tn ; nsv=1 ).U[:, 1] push!(u, un) end U = ttt(u[1],u[2]) for n=3:N U = ttt(U, u[n]) end println(size(U)) lammda = innerprod(T, U) X = lammda .* U return X end T = [ 1 -1 0 1 3 im 0 1 ; 0.0 1 -im 1 1 0 2 -2im] T = matten(T, 1, [2,2,2,2]) X_THOSVD = THOSVD(T)
Julia でSVD をするときに,Lapackを使って
using LinearAlgebra n = 10 A = rand(n, n) svd(A)
としても良いのですが,これだとO(n3)必要ですね. ランクをrにするのに,完全なSVDをする必要はありません.Arpackのsvdsを使うべし.
using Arpack n = 10 r = 5 A = rand(n, n) svd = svds(A ; nsv=r, ritzvec=true)[1] Ar = svd.U * diagm(svd.S) * svd.Vt
で10×10行列Aの5ランク近似がO(n2 r)で手に入ります.
実際に時間はかってみるとこんな感じ.
Arpackのほうがだいぶはやいが,rが大きいときは,Lapackの方がはやいっぽい.
using LinearAlgebra using Arpack n = 2000 A = rand(n, n) @time svd(A); # 4.236471 seconds (12 allocations: 183.350 MiB, 3.53% gc time) r = 5 @time svds(A ; nsv=r, ritzvec=true)[1]; # 0.479803 seconds (1.35 k allocations: 840.125 KiB) r = 10 @time svds(A ; nsv=r, ritzvec=true)[1]; # 0.654874 seconds (1.78 k allocations: 1.237 MiB) r = 100 @time svds(A ; nsv=r, ritzvec=true)[1]; # 1.538005 seconds (3.57 k allocations: 11.446 MiB) r = 200 @time svds(A ; nsv=r, ritzvec=true)[1]; # 2.692379 seconds (5.21 k allocations: 23.644 MiB) r = 400 @time svds(A ; nsv=r, ritzvec=true)[1]; # 5.119713 seconds (7.29 k allocations: 50.736 MiB)
関連記事
pythonのnp.squeezeをjulia言語でやるなら,dropdimsを使うと良い.juliaにも昔は'squeeze'関数があったっぽいが,今は消えてしまった?
collectを使うと良いです.
tup = (1,2,3,4,5) ary = collect(tup)
これで配列arrayに直されます.
行列の低ランク近似がSVDによって実現されるように,テンソルの低(タッカー)ランク近似がHOSVDで実現できます.
なお,Eckart Youngの定理より,SVDがフロベニウスノルムの意味で最良低ランク近似を実現しますが,テンソルの場合はそのような保証はないと思います.
テンソルにおいては,タッカーランクとCPランクという異なるランクの定義が存在します.(以下,研究室のセミナーで用いた資料.間違ってたらゴメン)


記号×_nはモードn積です.モード積の定義はこちらを参考にすると良いと思います.
juliaでHOSVDがさくっとできないかいろいろ試してましたが,TensorToolboxを使うのが手っ取り早そうですね.例として3×3×3テンソルTをHOSVDによってタッカーランク(2,2,2)で近似するJuliaコードは以下.
using TensorToolbox function HOSVD(T, reqrank) X = hosvd(T, reqrank=reqrank) g = X.cten Us = X.fmat #X = ttm(g, [Us[1],Us[2],Us[3]],[1,2,3]) X = ttm(g, [Us...]) return X end T = rand(3,3,3) println("input tensor") display(T) X = HOSVD(T, [2,2,2]) println("\n\noutput tensor") display(X) println("\n\nerror") println(norm(X-T))
タッカーランクを[3,3,3]にすると,エラーが0になります.
X.cten でコアテンソルが取り出せて,X.fmat でスライドでいうところのU_1,U_2,…を取り出しています.
ttmの使い方はgithubに丁寧に載ってます.ttm(X, A, 2)がXとAのモード2積 X ×_2 A です.
ところで,この実装って Truncated HOSVD になっているのだろうか...
3×3×3のテンソルを用意したいときは,X = rand(3,3,3) みたいにするとおもいますが,階数が大きい時に X = rand(i1,i2,i3,i4, ..., ,in って手動で入力するのが大変だったので,i = [i1,i2,i3,…,in] を用意して
using TensorToolbox
X = diagt(i)
みたくしてたけど,どうもX = rand(i...) で良いらしい.... は splat演算子というらしく,ドキュメントにもちゃんと記述がある.
docs.julialang.org
n階のテンソルの初式化をするなら,
X = Array{Float64, n}(undef, i...)
のようにすればよいね.
IBISに参加してみて,「行列分解の研究をしているの行列分解をあんまりよく理解していないな,確率的主成分分析でも勉強するか」と思い,中島変分ベイズの3-5,3-8,6章のほとんど,7章の全てを読んでみた.
須山ベイズを読み込んでいたので,スムーズに読めた.ベイズをやっていれば,繰り返し参照するであろう計算がかなり丁寧に整理されているので手元にあると便利だと思う.Notationもよく整理されていて読みやすかった.
変分ベイズの一般論
↓
応用例として行列分解モデル
↓
実は行列分解モデルって大域解が解析的に求まるので理論的な探求をしてみましょう(7章)
っていう展開が私的には凄く良かった.というか,行列分解モデルを変分ベイズで解こうとすると,大域解って求まるんですね,すごい.要は確率的行列分解は,SVDとコンシステントです,ってことだとは思うんだけど,全然知らなかったのでかなりワクワクして読んだ.この辺り,大事な補題の証明は載ってないけど,refがついているからフォローできるんじゃないかな(私はフォローしてない).アルゴリズムは私くらいのコーディングスキルの人間でも実装できるレベルで書いてある(実装してないけど).Juliaもくもく会とかで実装してみようかな.
他のベイズのアプリケーションの本を知らないので,比較できないけど,私のような初学者にとって,7章は驚きに満ちた章だった.普通の変分ベイズの大域解だけじゃなくて,経験変分ベイズの大域解までちゃんと載せるの,著者の情熱を感じるよね.
LDAに関する議論もたくさんあるのでもう少し読み込んでみるつもり.これから機械学習始めます,みたいな人にはおすすめできないけど,須山ベイズをやり切ったくらいの体力がある人はぜひ手に取ってみるといいと思う.本当に7章は勉強になった.他の章も,縮小カーネル回帰とか,協調フィルタリングとか,私の研究テーマ近傍の話もあって,とても有益だった.
ちなみに,須山ベイズはめっちゃ良い本なので,機械学習やる人なら絶対に読んだ方が良いです.須山ベイズの方は入門向けと思う.
ただのメモです.
行列Aに対して,exp(A) とすると,行列指数関数が発動されてしまう.
element-wiseに演算をしたいときは,.を使う.
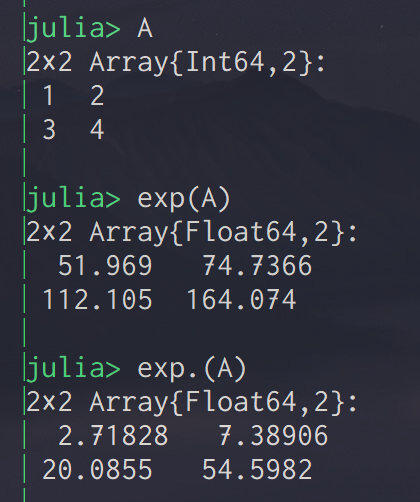
exp.(A)で各要素ごとにexpされる.
A*Bは行列毎の積だけど,A.*Bにすると,要素積になる.
