小針先生の確率統計の本を読んだ.教訓がたくさん詰まった本当に良い本だったと思う.6章の「酔歩」がとても印象に残っている.独立した章なので,確率の基本的なことが分かっていれば読める.

時刻t=0で原点に居る酔っ払いが,確率1/2で西へ,確率1/2で東に一歩進むランダムウォークを考えると,原点付近をうろちょろしそうだけど,まぁ,冷静に考えればそんなことはない.Juliaで酔っぱらいを召喚して,実験してみる.
function random_walker(n_steps) traj = [0] for step = 1 : n_steps coin = rand() pos = traj[step] if coin > 0.5 append!(traj, pos + 1) else append!(traj, pos - 1) end println("step: $step pos: $pos") end return traj end
trajに各ステップでの酔っぱらいの位置が保存される.とりあえず酔っぱらいを5人くらい召喚しよう.
using Plots function main(n_walkers) n_steps = 30000 fnt = font(16, "times") p_r = plot(legend = :topleft) for walker = 1:n_walkers traj = random_walker(n_steps) plot!(p_r, [1:n_steps+1;], traj, xlabel = "step", ylabel = "pos", xguidefont = fnt, yguidefont = fnt, xtickfont = fnt, ytickfont = fnt, titlefont = fnt, title = "trajectory of radom walkers", size = (1200, 600), linewidth = 3, label = "random_walker $walker") end plot!([0.0], st=:hline, label=false) savefig(p_r, "traj_rw.png") end main(5)
これをプロットしてみる.横軸がステップ数,縦軸が酔っぱらいの位置である.
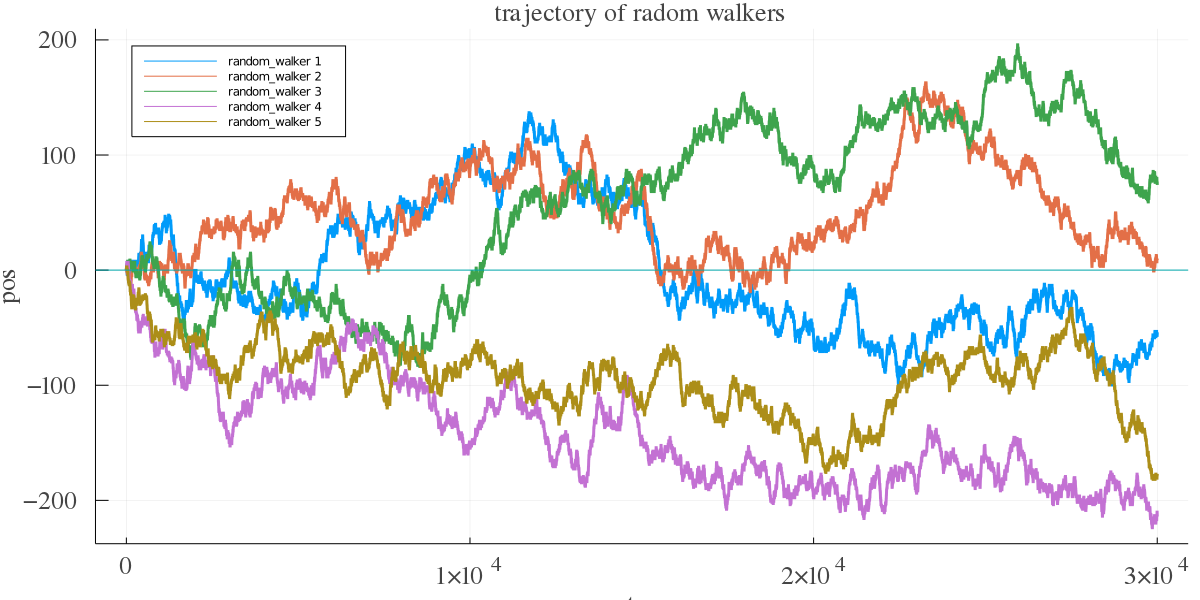
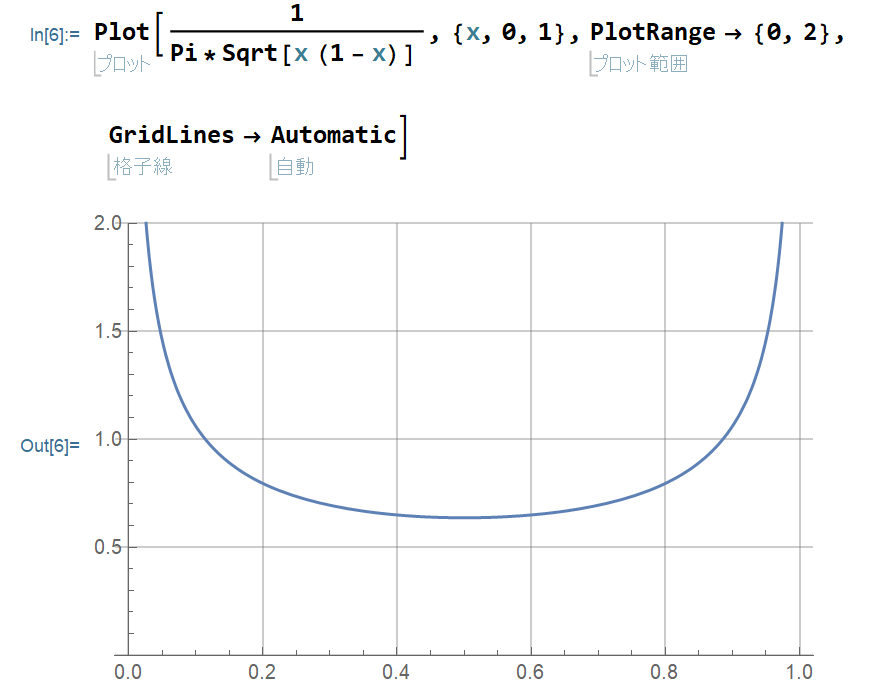
観ての通り,原点付近をうろちょろしているわけじゃない.実は,単位時間あたりに原点より東に居る時間をx,西に居る時間を1-xとすると,この分布は
p(x) = (π√(x(1-x)))-1
になって,東か西かのどちらか片方ばかりに多くいる確率の方が大きい.
また,どんなに長い時間観測しても,「1度も原点に戻らない」確率と「1度しか原点に戻らない」確率が最も大きく,m回復帰する確率は,mが大きいほど小さいことが示せる.この話は,小針先生の「確率・統計入門」の第6章「酔歩」に証明を含め詳しく議論されてる.古い本だけど,とても読みやすい.独特の言い回しで著者の息遣いが聞こえてくるすごい良い本だと思う.例えば,このランダムウォークに関して小針先生は
正の領域に居る時は善行,負の領域に居る時は悪行を行っている時間とすると,善悪半々というマジメ人間は最も少く,悪い奴ほどはびこり,あるいは善人ほど多いということなのである.これは真実かもしれない p148
とか,
原点のまわりをウロウロするという最初の予想に反して,それほどセンチメンタルに故郷を慕うのではない p154
とかしゃれたことを言うのである.楽しい.
特に最初の第一章は「円に任意の弦をひくとき,その長さが内接正三角形の一片より長くなる確率を求めよ」という例題に対してA君B君C君の異なる回答の総括として,
真理というものがどこかにあって、それを探究するのが学問、ではなくて、何を仮定すれば何が結論されるかの論理の連鎖が学問である。
と言っていて,読んでて興奮するものがある.
どうやら小針先生はこの本を完成させることなく急逝し,旧友たちがこの本を完成させたようである.この本の前書きやあとがきには,なかなかドラマを感じるので,本屋で見かけたらぜひ手に取ってみたらどうだろう.
全然関係ないけど,酔歩つながりで,「酔歩する男」っていう物語がある.玩具修理者に収録されている.これがなかなか鳥肌の立つよいタイムリープ系SFで面白いのです.



